Mini Project III | likelion |
[ MiniProject III ] 월간 데이콘 신용카드 사용자 연체 예측 AI 경진대회
🦁 Project
멋쟁이사자처럼 AI School 7th MiniProject 3
🙆♀️🙆 Team 7ㅏ즈아
으쌰으쌰2팀 - 이승후, 상우진, 남하윤, 김준모
🗓️ When
2022.11.02 - 2022.11.06

이번 미니 프로젝트로 7ㅏ즈아 팀은 2021년 5월에 마감한 월간 데이콘 신용카드 사용자 연체 예측 AI 경진대회를 주제로 모델을 만들고 높은 성능을 낼 수 있는 방법에 대해 모색하기로 하였다.
🗂️ Dataset
- index
- gender: 성별
- car: 차량 소유 여부
- reality: 부동산 소유 여부
- child_num: 자녀 수
- income_total: 연간 소득
- income_type: 소득 분류
['Commercial associate', 'Working', 'State servant', 'Pensioner', 'Student'] - edu_type: 교육 수준
['Higher education' ,'Secondary / secondary special', 'Incomplete higher', 'Lower secondary', 'Academic degree'] - family_type: 결혼 여부
['Married', 'Civil marriage', 'Separated', 'Single / not married', 'Widow'] - house_type: 생활 방식
['Municipal apartment', 'House / apartment', 'With parents', 'Co-op apartment', 'Rented apartment', 'Office apartment'] -
DAYS_BIRTH: 출생일
데이터 수집 당시 (0)부터 역으로 셈.
즉, -1은 데이터 수집일 하루 전에 태어났음을 의미 -
DAYS_EMPLOYED: 업무 시작일
데이터 수집 당시 (0)부터 역으로 셈.
즉, -1은 데이터 수집일 하루 전부터 일을 시작함을 의미.
양수 값은 고용되지 않은 상태를 의미함. - FLAG_MOBIL: 핸드폰 소유 여부
- work_phone: 업무용 전화 소유 여부
- phone: 전화 소유 여부
- email: 이메일 소유 여부
- occyp_type: 직업 유형
- family_size: 가족 규모
-
begin_month: 신용카드 발급 월
데이터 수집 당시 (0)부터 역으로 셈, 즉, -1은 데이터 수집일 한 달 전에 신용카드를 발급함을 의미 - credit: 사용자의 신용카드 대금 연체를 기준으로 한 신용도
=> 낮을수록 높은 신용의 신용카드 사용자를 의미함
💻 Closer Look
우선 기본으로 제공되는 sample_submission.csv를 그대로 제출하니 0.88113 / 0.87223 (Public / Private) 의 성능이 나왔다. 해당 Baseline 코드는 Random Forest Classifer을 사용했다.
1. Binary variables
train['gender'] = train['gender'].replace(['F','M'],[0,1])
test['gender'] = test['gender'].replace(['F','M'],[0,1])
print('gender :')
print(train['gender'].value_counts())
print('--------------')
print('Having a car or not : ')
train['car'] = train['car'].replace(['N','Y'],[0,1])
test['car'] = test['car'].replace(['N','Y'],[0,1])
print(train['car'].value_counts())
print('--------------')
print('Having house reality or not: ')
train['reality'] = train['reality'].replace(['N','Y'],[0,1])
test['reality'] = test['reality'].replace(['N','Y'],[0,1])
print(train['reality'].value_counts())
print('--------------')
print('Having a phone or not: ')
print(train['phone'].value_counts())
print('--------------')
print('Having a email or not: ')
print(train['email'].value_counts())
print('--------------')
print('Having a work phone or not: ')
print(train['work_phone'].value_counts())
print('--------------')
2. Child_num
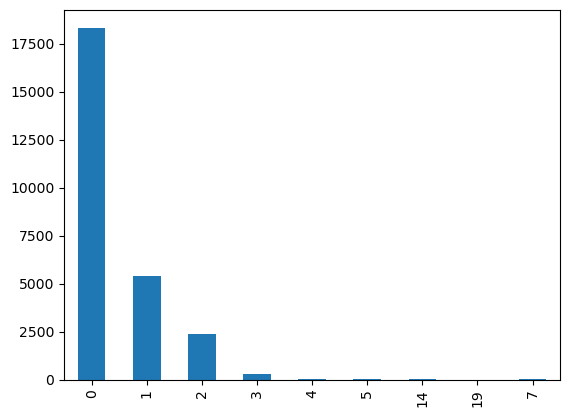
child_num 값이 3보다 크면 희소값으로 판단하여 3으로 값을 통일해주었다.
train['child_num'].value_counts(sort=False).plot.bar()
train.loc[train['child_num'] >= 3,'child_num']=3
test.loc[test['child_num'] >= 3, 'child_num']=3
3. Family_size
train['family_size'].value_counts().sort_values(ascending = False)
2.0 14106
1.0 5109
3.0 4632
4.0 2260
5.0 291
6.0 44
7.0 9
15.0 3
9.0 2
20.0 1
Name: family_size, dtype: int64
famliy_size가 7보다 크면 희소값이라고 판단하여 7로 모두 값을 통일해주었다.
train.loc[train['family_size'] > 7, 'family_size'] = 7
test.loc[test['family_size'] > 7, 'family_size'] = 7
4. income
income가 넓게 퍼져 있다. 스케일링해준 후 범주화하여 시각화해보자.
train['income_total'] = train['income_total'].astype(object)
train['income_total'] = train['income_total']/10000
test['income_total'] = test['income_total']/10000
##############################################################3
print(train['income_total'].value_counts(bins=10,sort=False))
train['income_total'].plot(kind='hist',bins=50,density=True)
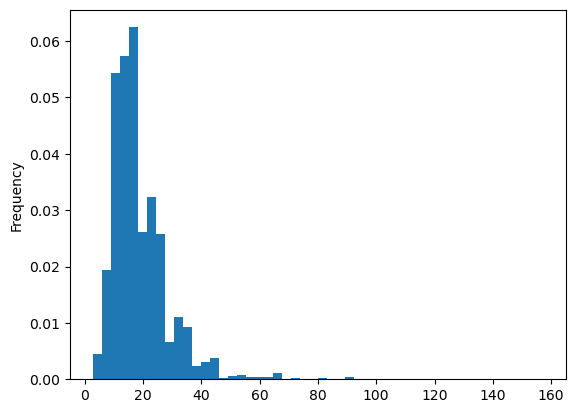
소득의 평균값도 계산하여 추가해주자.
train['income_mean'] = train['income_total'] / train['family_size']
test['income_mean'] = test['income_total'] / test['family_size']
train['income_mean']
총소득 범주화해주기!!
count, bin_dividers =np.histogram(train['income_total'], bins=7)
bin_names=['소득'+str(i) for i in range(7) ]
#bin_dividers는 train기준!!
train['income_total']=pd.cut(x=train['income_total'], bins=bin_dividers, labels=bin_names, include_lowest=True)
test['income_total']=pd.cut(x=test['income_total'], bins=bin_dividers, labels=bin_names, include_lowest=True)
5. Label Encoding
from sklearn import preprocessing
label_encoder=preprocessing.LabelEncoder()
train['income_type']=label_encoder.fit_transform(train['income_type'])
test['income_type']=label_encoder.transform(test['income_type'])
########################################################################
train['edu_type']=label_encoder.fit_transform(train['edu_type'])
test['edu_type']=label_encoder.transform(test['edu_type'])
########################################################################
train['family_type']=label_encoder.fit_transform(train['family_type'])
test['family_type']=label_encoder.transform(test['family_type'])
########################################################################
train['house_type']=label_encoder.fit_transform(train['house_type'])
test['house_type']=label_encoder.transform(test['house_type'])
########################################################################
train['income_total']=label_encoder.fit_transform(train['income_total'])
test['income_total']=label_encoder.fit_transform(test['income_total'])
########################################################################
train['occyp_type']=label_encoder.fit_transform(train['occyp_type'])
test['occyp_type']=label_encoder.fit_transform(test['occyp_type'])
6. Minus continuous variables
def make_bin(variable, n):
train[variable]=-train[variable]
test[variable]=-test[variable]
count, bin_dividers =np.histogram(train[variable], bins=n) #train의 구간화를 적용
bin_names=[str(i) for i in range(n)]
train[variable]=pd.cut(x=train[variable], bins=bin_dividers, labels=bin_names, include_lowest=True)
test[variable]=pd.cut(x=test[variable], bins=bin_dividers, labels=bin_names, include_lowest=True)
test[variable].fillna(str(0), inplace=True) #test에는 없는 것을 임의의 값으로 채움
##########################################################
train[variable]=label_encoder.fit_transform(train[variable])
test[variable]=label_encoder.transform(test[variable])
bins를 나눠준 기준은 다음과 같이 생각했다.
# DAYS_BIRTH
# 출생일
# 최대 - 최소 = 17,447 (일) = 581 (개월) = 48.46 (년) -> 약 50 (년)
# DAYS_EMPLOYED
# 업무 시작일
# 최대 - 최소 = 380,956 (일) = 12698.53 (개월) = 1058 (년)
# 양수 값 처리 -> 고용되지 않은 상태임 -> 0
# 처리 후 -> 523 (개월) -> 약 43.64 (년)
# begin_month
# 신용카드 발급월
# 최대 - 최소 = 60 (개월) = 5 (년)
train.loc[train['DAYS_EMPLOYED'] > 0,'DAYS_EMPLOYED'] = 0
test.loc[test['DAYS_EMPLOYED'] > 0, 'DAYS_EMPLOYED'] = 0
train['Age'] = train['DAYS_BIRTH'] // 365
test['Age'] = test['DAYS_BIRTH'] // 365
make_bin('DAYS_BIRTH', n=10)
make_bin('DAYS_EMPLOYED', n=4)
make_bin('begin_month', n=5)
7. Correlation
plt.figure(figsize = (14, 6))
sns.heatmap(train.corr(), fmt = '.2f',
# vmin = -0.5, vmax = 0.5,
annot = True,
cmap = 'coolwarm')
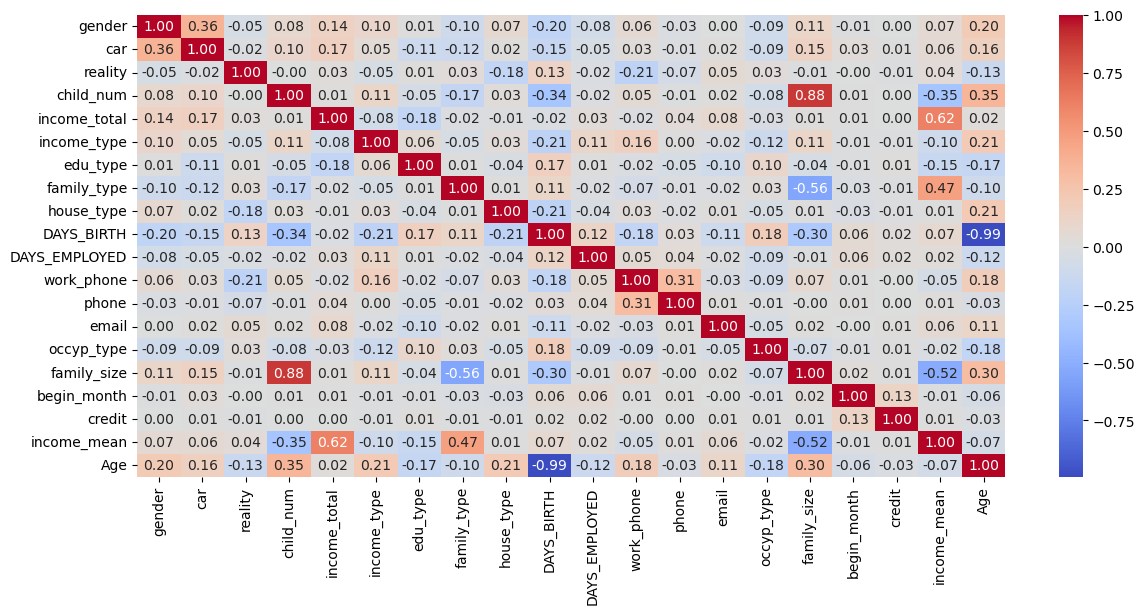
8. Modeling
CatBoost Classifer를 이용해 모델을 학습시켜주었다.
clf = CatBoostClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict_proba(X_val)
# print(f"log_loss: {log_loss(to_categorical(y_val['credit']), y_pred)}")
print(f"log_loss: {log_loss(y_val['credit'], y_pred)}")
log_loss_val = log_loss(y_val['credit'], y_pred)
log_loss_val = np.around(log_loss_val, 3)
log_loss(y_val['credit'], y_pred)
=> 0.8091264167319345
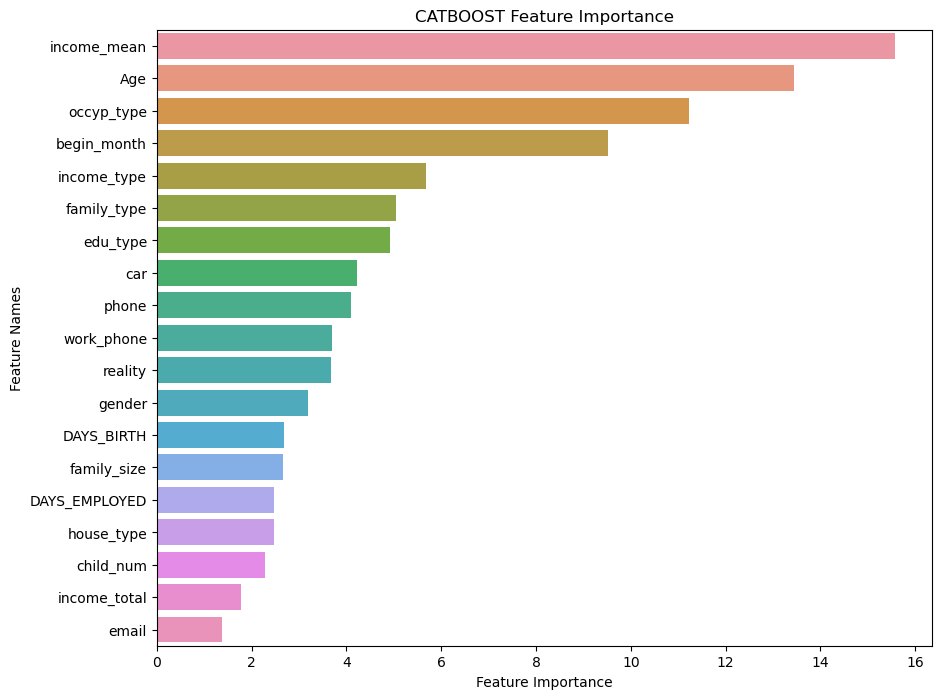
9. Feature importance 시각화
def plot_feature_importance(importance, names, model_type):
feature_importance = np.array(importance)
feature_names = np.array(names)
data = {'feature_names': feature_names,
'feature_importance': feature_importance}
fi_df = pd.DataFrame(data)
fi_df.sort_values(by=['feature_importance'], ascending=False, inplace=True)
plt.figure(figsize=(10, 8))
sns.barplot(x=fi_df['feature_importance'], y=fi_df['feature_names'])
plt.title(model_type + ' Feature Importance')
plt.xlabel('Feature Importance')
plt.ylabel('Feature Names')
plot_feature_importance(clf.get_feature_importance(),test_x.columns,'CATBOOST')
10. Cross Validation
from sklearn.model_selection import KFold, StratifiedKFold
def run_kfold(clf):
folds=StratifiedKFold(n_splits=5, shuffle=True, random_state=55)
outcomes=[]
sub=np.zeros((test_x.shape[0], 3))
for n_fold, (train_index, val_index) in enumerate(folds.split(train_x, train_y)):
X_train, X_val = train_x.iloc[train_index], train_x.iloc[val_index]
y_train, y_val = train_y.iloc[train_index], train_y.iloc[val_index]
clf.fit(X_train, y_train)
predictions=clf.predict_proba(X_val)
logloss=log_loss(y_val['credit'], predictions)
outcomes.append(logloss)
print(f"FOLD {n_fold} : logloss:{logloss}")
sub+=clf.predict_proba(test_x)
mean_outcome=np.mean(outcomes)
print("Mean:{}".format(mean_outcome))
return sub/folds.n_splits
my_submission = run_kfold(clf)
➡️ 시도 History와 최종 성능 비교
History
| Baseline | Final Score |
|---|---|
| 0.872 | 0.7836 |
# basline => 0.88
# 점수 : ( Public / Private )
########## RandomFroest ##########
# 1
# baseline_submission_0.983 -> 0.86583 / 0.8516
# 직업유형(occyp_type) label encoding
# 2
# baseline_submission_0.951 -> 0.86071 / 0.8465
# DAYS_EMPLOYED 양수 처리
# 3
# baseline_submission_0.923 -> 0.85454
# DAYS_BIRTH / DAYS_EMPLOYED / begin_month 통계자료 -> bins 개수 조정
############ XGBoost ############
# 4
# baseline_submission_0.856 -> 0.8738 / 0.8654
# XGBoost
# 오히려 성능이 더 떨어짐
########## CatBoost ##########
# 5
# baseline_submission_0.824 -> 0.8013 / 0.7931
# 결측치 제거
# 의미 없는 컬럼 제거 : index, FLAG_MOBIL
# FLAG_MOBIL : 전부 1로, 동일한 값을 가짐
# 6
# baseline_submission_0.819 -> 0.7978 / 0.7978
# Age 컬럼 추가
# 7
# baseline_submission_0.821
# family_size 7 이상 통일
# 8
# 성능 저하 -> # 9에서 DAYS_BIRTH 살리기
# DAYS_BIRTH, work_phone
# work_phone : credit과의 상관계수 0
# 9
# baseline_submission_0.808 -> 0.7904 / 0.7836
# work_phone 컬럼만 제외, DAYS_BIRTH 살리고
# income_mean 계산
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).