Table of Contents
[ 논문 구현 + 개선 ] 설명 가능한 AI 를 활용한 신용평가모델
최근, 금융(Finance)과 IT 기술(technology)을 결합한 서비스, 핀테크(FinTech)가 주목을 받고 있다. 이런 뉴스를 접하면서 나도 자연스럽게 금융 쪽에 관심이 생기면서 관련 정보를 많이 찾아보게 되었다. 이번 포스트는 인공지능을 이용해 신용평가 모형에 대한 연구한 논문을 바탕으로 구현한 내용을 정리할 예정이다. 가장 높은 성능을 냈던 모델들을 가져와서 구현한다. 활용한 데이터셋은 조금 차이가 있어 보인다.
🗂 Reference
천예은, 김세빈, 이자윤, 우지환, 설명 가능한 AI 기술을 활용한 신용평가 모형에 대한 연구, 한국데이터정보과학회지(2021).
📚 데이터셋
kaggle Home Equity Line of Credit(HELOC)
Dataset은 10459개의 데이터로 이루어져있으며, y 라벨 중 5000개는 ‘Good’, 5459개는 ‘Bad’에 속한다. 이때 ‘Good’과 ‘Bad’는 각각 대출 가능과 대출 불가능을 나타낸다.
ExternalRiskEstimate- 위험 지표의 통합 지표(폴란드 BIK의 비율에 해당)MSinceOldestTradeOpen- 최초 거래 이후 경과된 개월 수MSinceMostRecentTradeOpen- 마지막으로 열린 거래 이후 경과된 개월 수AverageMInFile- 파일에 있는 평균 개월NumSatisfactoryTrades- 만족스러운 거래 횟수NumTrades60Ever2DerogPubRec- 60회 이상 연체된 거래 건수NumTrades90Ever2DerogPubRec- 90회 이상 연체된 거래 건수PercentTradesNeverDelq- 연체되지 않은 거래 비율MSinceMostRecentDelq- 마지막 연체 거래 이후 경과된 개월 수MaxDelq2PublicRecLast12M- 최근 12개월 중 가장 긴 연체기간MaxDelqEver- 가장 긴 연체 기간NumTotalTrades- 총 거래 횟수NumTradesOpeninLast12M- 지난 12개월 동안 열린 거래 수PercentInstallTrades- 할부 거래 비율MSinceMostRecentInqexcl7days- 마지막 문의 이후 개월(최근 7일 제외)NumInqLast6M- 최근 6개월간 문의 건수NumInqLast6Mexcl7days- 최근 6개월간 문의 건수(최근 7일 제외)NetFractionRevolvingBurden- 회전잔액을 신용한도로 나눈 것NetFractionInstallBurden- 할부 잔액을 원래 대출 금액으로 나눈 값NumRevolvingTradesWBalance- 잔액이 있는 회전 거래 수NumInstallTradesWBalance- 잔액이 있는 할부 거래 횟수NumBank2NatlTradesWHighUtilization- 이용률이 높은 거래 건수(신용 이용률 - 신용 한도 대비 신용카드 잔액)PercentTradesWBalance- 잔액이 있는 거래의 비율
출처 : https://pbiecek.github.io/xai_stories/story-heloc-credits.html
💻 구현 Implementation
1. 데이터 확인 및 전처리
데이터 타입 확인
df = pd.read_csv("heloc_dataset.csv")
df.info()
결측치 확인
df.isnull().sum()
범주형 데이터 one-hot-encoding해주기
데이터의 컬럼 중 MaxDelqEver는 가장 큰 채무 불이행을 나타내며, 범주형 변수로 one-hot-encoding을 시행해준다.
print(X['MaxDelqEver'].unique())
one_hot_encoding = pd.get_dummies(X['MaxDelqEver'])
one_hot_encoding[:5]
one-hot-encoding해서 MaxDelqEver 값 대체해주기
X = pd.concat([X, one_hot_encoding], axis = 1).drop('MaxDelqEver', axis = 1)
X.head()
2. train data와 test data 나눠주기
이때, 전체데이터를 1:1 비율로 train data와 test data로 분할해준다. 이는 나중에 모델1의 학습데이터와 평가데이터로 들어갈 예정이다. y값의 비율을 기준으로 분할해주었다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42, stratify=y)
y_test.value_counts()
3. 모델1 구현 - 대출가능확률 예측 모델
모델1은 대출 가능한 확률을 예측한다. 모델1을 통해 얻은 확률 값을 평가데이터의 레이블로 대체해준다. 이유는 각 사람의 신용평가수준이 모두 동일하지 않으며, 대출 가능 범위에서도 다양하게 분포하고 있을 것이라 가정했기 때문이다.
모델1 학습 - XGBoostRegressor
자신의 notebook에 xgboost가 설치되어있지 않으면 다음 코드를 실행해주면 된다.
!pip install xgboost
이제 xgboost regressor을 이용해 학습시켜주겠다.
import xgboost as xgb
model_xgb=xgb.XGBRegressor(n_estimators=100, learning_rate=0.05, gamma=0, subsample=0.75,
colsample_bytree=0.3, max_depth=7, random_state = 42)
model_xgb.fit(X_train,y_train)
pred_xgb = model_xgb.predict(X_test)
pred_xgb_train = model_xgb.predict(X_train)
실제 레이블과 방향성이 일치하는 데이터만을 추출
모델1의 불확실성의 영향을 최소화하기 위해, 실제 레이블과 방향성이 같은 평가데이터만 추출해서 사용한다. 대출가능확률이 0.5 이상인 데이터는 대출가능으로, 대출가능확률이 0.5 이하인 데이터는 대출 불가능으로 판단한다.
실제 레이블과 방향성이 일치하는 평가데이터만을 가져와서 모델1에서 얻은 대출가능확률 값으로 대체해주었다. 확률값은 반올림하여 소숫점 둘째자리까지 나타내주었다.
X_test_xgb = X_test[np.around(pred_xgb) == y_test].reset_index(drop = True)
y_test_xgb = np.round_(pred_xgb[np.around(pred_xgb) == y_test],2)
X와 y를 합쳐서 하나의 데이터프레임으로 만들기
y_test_xgb = pd.DataFrame(y_test_xgb)
y_test_xgb.columns = ['RiskPerformance']
y_test_xgb
test_xgb = pd.concat([X_test_xgb, y_test_xgb], axis = 1)
test_xgb
이렇게 얻은 test_xgb를 df_model1_xgb.csv로 저장해주겠다.
4. 모델2 구현 - 신용평가등급 모델
- Input : 신용변수 변화량
- Output : 대출 가능한 확률의 변화량
Dataset sampling 및 가공
추출된 데이터 셋에서 무작위로 샘플 두개씩을 선택 후 각 변수별 변화량을 계산하여 새로운 데이터 셋을 생성하였다.
모델1로 새로 만들어주었던 데이터 ‘df_model1_xgb.csv’를 불러와서 사용한다. 논문에서는 무작위로 샘플 두 개씩을 선택하여 각 변수별 변화량을 계산했지만, 나는 데이터셋에서 100,000개씩 불러와서 빼준 후 중복값을 drop 해주는 것으로 대체해주었다.
df_diff = df_new.sample(n = 100000, replace = True).reset_index(drop = True) - df_new.sample(n = 100000, replace = True).reset_index(drop = True)
df_diff = df_diff.drop_duplicates().reset_index(drop = True)
train - test data 분할
전체 데이터셋에서 train data와 test data의 비율을 train : test = 8 : 2로 나눠준다.
X_train_n, X_test_n, y_train_n, y_test_n = train_test_split(X_diff, y_diff, test_size=0.2, random_state=42)
모델2 학습 - GBM Regressor
from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor
gbr_n = GradientBoostingRegressor(n_estimators=500, learning_rate=0.1,
max_depth=5, random_state=42).fit(X_train_n, y_train_n)
pred_gbr_train = gbr_n.predict(X_train_n)
pred_gbr = gbr_n.predict(X_test_n)
모델2의 성능 평가는 평균 제곱근 오차(root mean square error; RMSE)로 진행하였다. 논문에서는 검증평가 성능을 10-fold 교차검증(cross-validation)을 하여 RMSE를 구하였다.
print("Train score: ", sklearn.metrics.mean_squared_error(y_train_n, pred_gbr_train)**0.5)
print("Test score: ", sklearn.metrics.mean_squared_error(y_test_n, pred_gbr)**0.5)
성능은 다음과 같이 나온다.
Train score: 0.10046253737047732
Test score: 0.11249008610001081
5. 대출 가능 확률의 변화량에 영향을 준 변수 분석
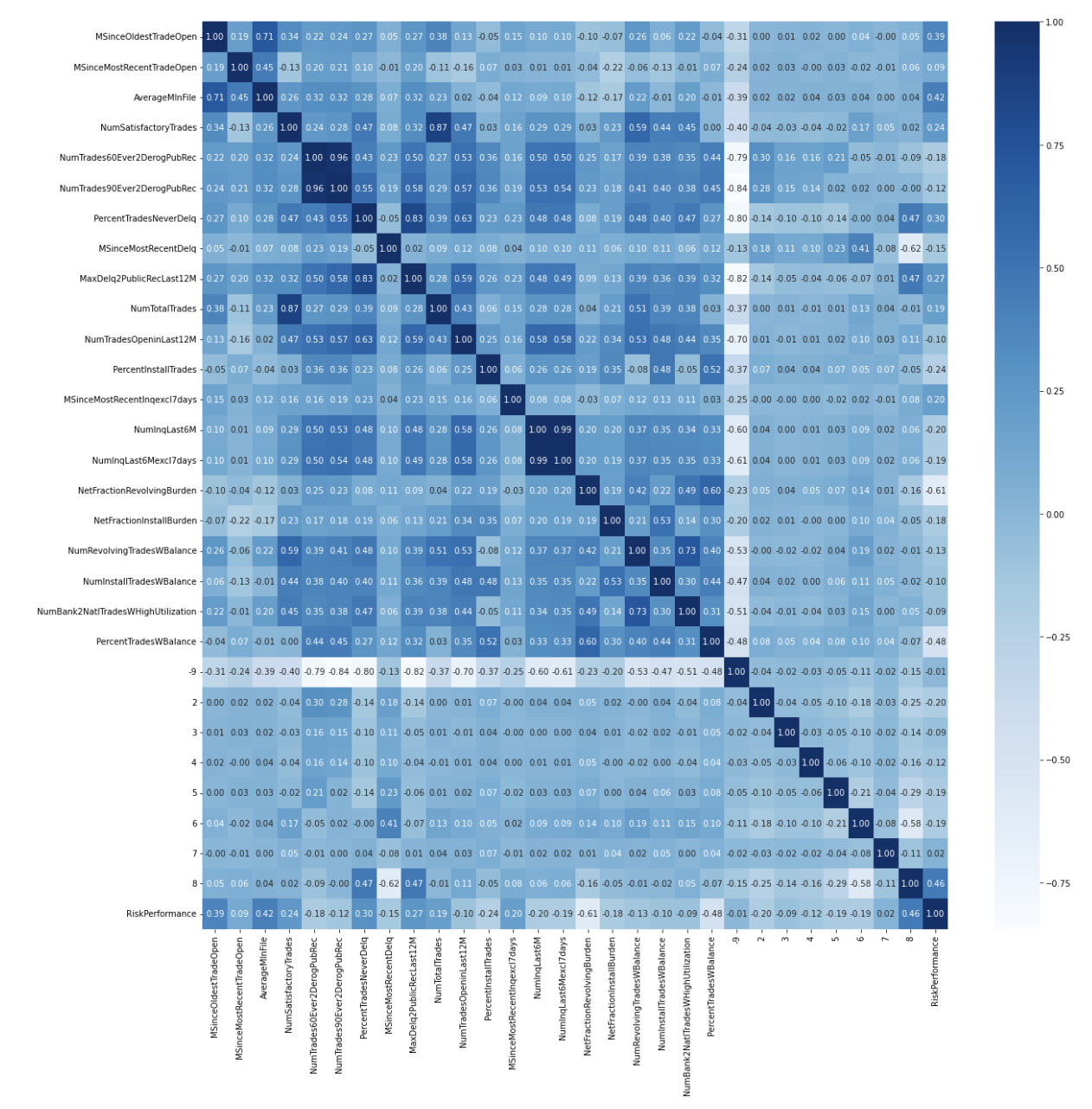
각 신용 변수에 대한 상관계수 시각화
plt.figure(figsize=(20,20))
sns.heatmap(data = df_diff.corr(), annot=True,
fmt = '.2f', cmap='Blues')
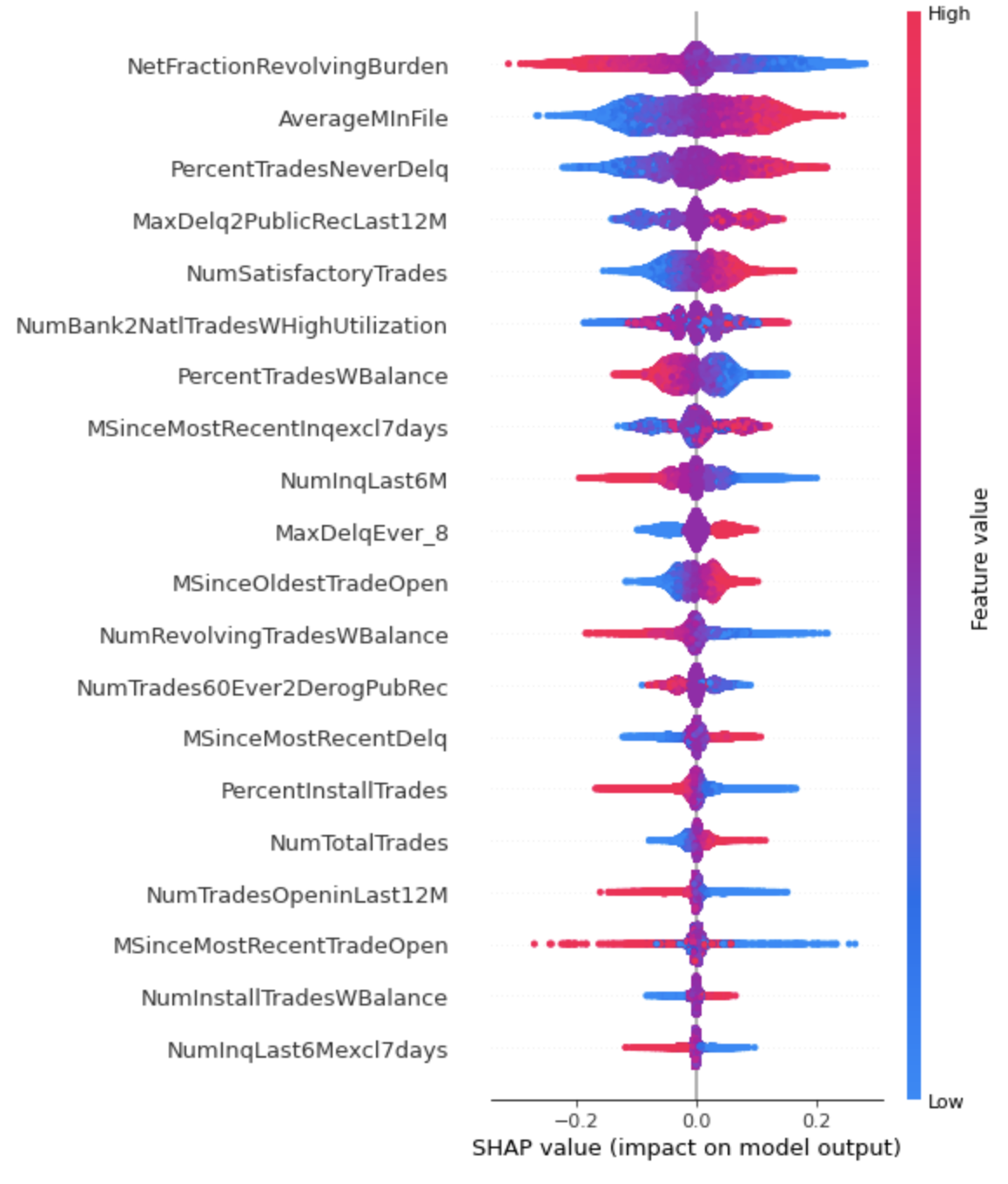
신용평가 등급 변화에 대한 Feature별 기여도 시각화
SHAP SHapley Additive exPlanation 은 “특정 변수가 제거” 되면 얼마나 예측에 변화를 주는지 살펴보고 그에 대한 답을 SHAP value로 표현한다. 즉, SHAP는 예측에 대한 각 특성의 기여도를 계산하여 instance x의 예측을 설명한다.
그럼 이제 SHAP를 이용하여 모델 2의 예측에 각 Feature들이 얼마나 기여했는지 분석해보겠다.
shap.summary_plot(shap_values, X_train_n)
➡️ 결론
머신러닝을 통해서 도출된 등급을 설명하기 위해서, 대리인 기반의 설명 가능한 인공지능 방법을 적용하 였다. 그 결과, 인공지능이 개인의 신용 등급을 평가하는 데 필요한 중요한 특징 변수들이 무엇, 무엇, 무엇 인지 확인할 수 있었다. 마지막으로 제안된 알고리즘을 통해서, 신용 등급이 변동되었을 때, 변동 원인이 되는 이유를 설명 할 수 있다. 이 부분은 기존의 설명 가능한 인공지능 알고리즘이 단순히 어떤 결과를 도출했을 때, 중요한 원인이 되는 특징들을 선별하는 데 그치는 한계를 극복하였다. 단순한 결과 설명 뿐만 아니라, 다른 두 결과 사이의 변동을 위한 방법을 제시하였다는 점에의 의의가 있다.
하지만, 제안된 알고리즘은 변화를 위한 최적의 방안을 제시하지는 못한다는 한계가 존재한다. 고객들이 필요한 것은 자신의 신용등급에 대한 설명뿐만 아니라, 다른 등급으로 이동하기 위한 방법이기 때문이다. 등급 변화를 위해 필요한 다양한 특징 변수들 중에서는 짧은 시간에 변화 시킬 수 없는 특징들 도 존재한다. 따라서 이러한 특징 변수들의 특성에 대한 이해를 바탕으로, 최소한의 노력으로 최대의 등 급 변동의 효과를 설명할 수 있는 방법에 대한 연구가 뒷받침 된다면, 인공지능을 이용한 신용평가 서비 스 도입에 큰 도움이 될 것으로 기대한다.
Related Posts
| 구글코리아 x Project | LLM 기반 사내 데이터 분석 엔진, DBDeep | |
| Mini Project LikeLion | 청경채 성장 예측 | |
| Project | Weather Tour Application |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).