ML | Random Forest란?
복습 겸 다시 랜덤 포레스트의 개념을 정리해보고자 한다.
🌳 랜덤 포레스트란?
랜덤 포레스트란 지도학습 알고리즘으로 여러 개의 의사결정 나무(Decision Tree)를 조합한 모델로, 포레스트라는 이름이 붙었다.
의사결정 나무
의사결정나무는 쉽게 말하자면 if-else으로 나누어진 트리 모형으로, 하나의 특징(출력변수)을 골라 특정 기준 값에 따라 데이터 집합을 2개의 자식 마디로 분하란다. 분류 나무일 때는 출력변수가 범주형 변수가 될 것이고, 회귀 나무일 때는 추론하는 변수가 연속형 실수가 된다.
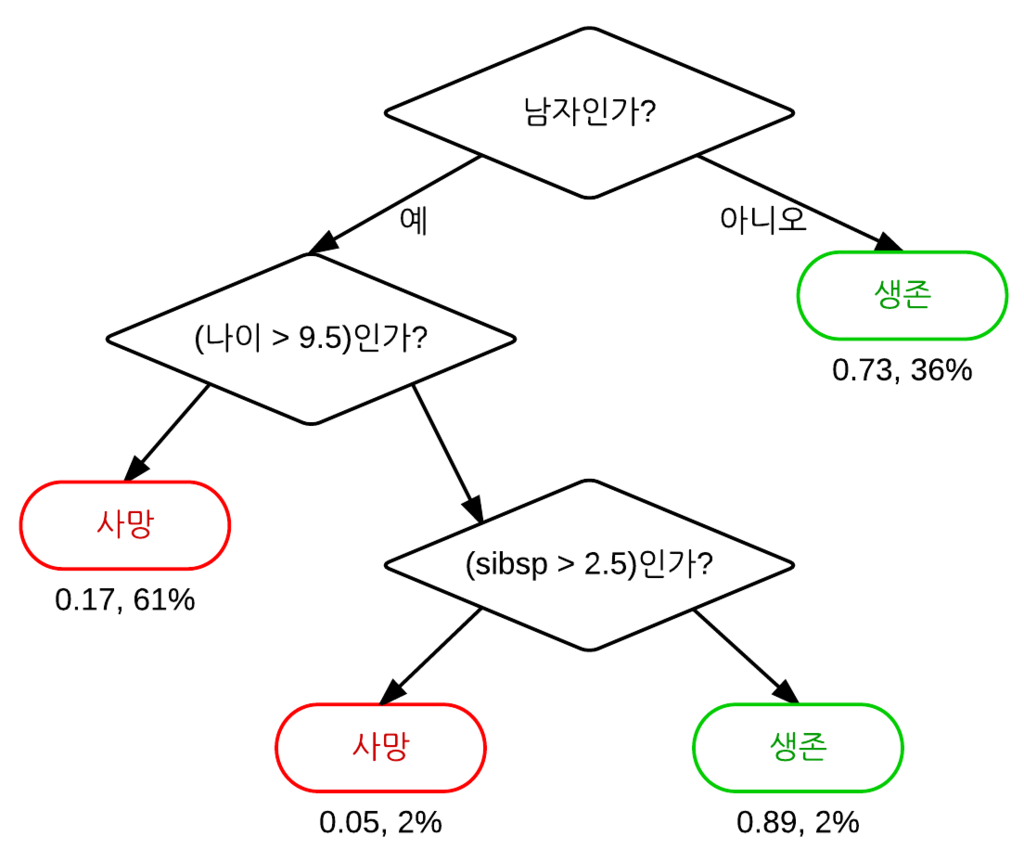
출처: Wikipedia
의사결정나무는 계산복잡성 대비 높은 예측을 내며, 변수 단위로 설명력을 지닌다는 강점을 가지고 있다. 다만 의사결정나무는 결정경계(Decision Boundary)가 데이터 축에 수직이어서 특정 데이터에만 잘 작동할 가능성이 높다.
이와 같은 문제를 극복하기 위해 등장한 모델이 바로 랜덤포레스트로, 같은 데이터에 대해 의사결정나무를 여러 개 만들어 그 결과를 종합해서 예측 성능을 높인다.
⚙️ 랜덤 포레스트 작동 방식: 배깅
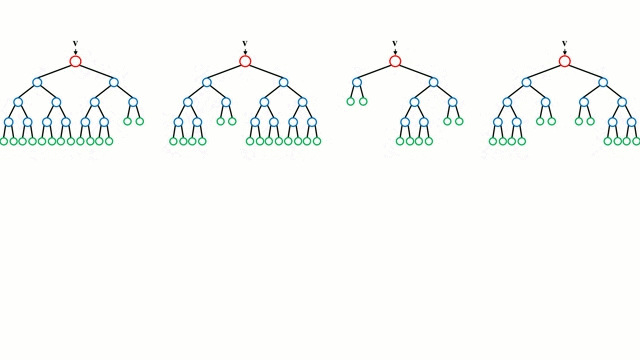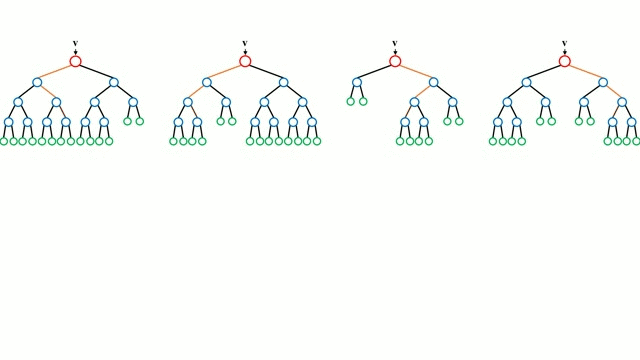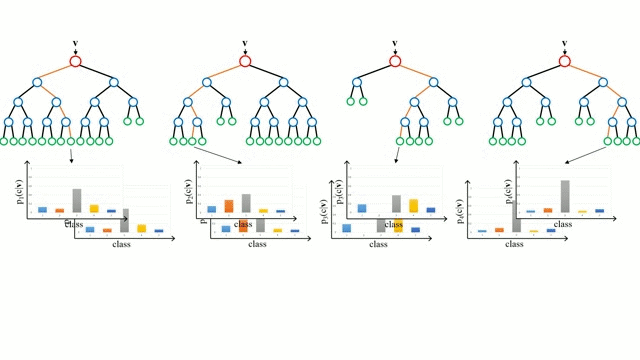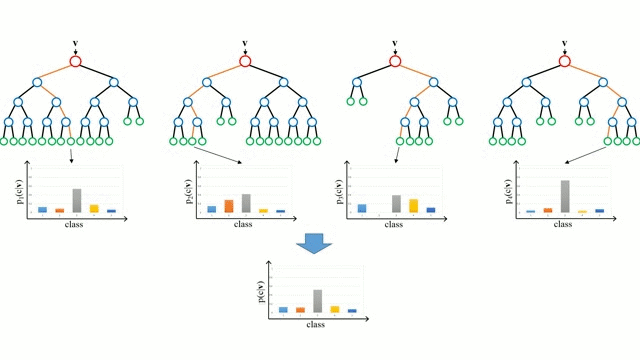
부트스트랩을 통해 다양한 서브 데이터셋을 생성하고 여러 개의 의사결정나무가 각각의 데이터셋을 학습하고 결과를 취합함으로써 단일 의사결정나무가 가질 수 있는 과적합 문제 를 해결할 수 있다.
출처: Wikipedia
이때 랜덤 포레스트가 의사결정나무를 이렇게 종합하는 방식을 배깅이라고 한다.
배깅(Bootstrap Aggregation, Bagging)이란?
배깅은 흔히 노이즈가 많은 데이터셋 내에서 분산을 줄이는 데 사용되는 앙상블 학습 기법이다. 앙상블 학습이란 다수의 기초 알고리즘을 결합하여 더 나은 성능의 예측 모델을 형성하는 것을 말하며, 랜덤포레스트는 분산을 줄이기 위해 사용된다. 부트스트랩(랜덤 샘플링)을 집계(aggregate)하여 학습 데이터가 충분하지 않더라도 충분한 학습 효과를 주어 bias의 underfitting 문제나 높은 분산으로 인한 overfitting 문제를 해결하는 데 도움을 준다.
출처: Wikipedia
💻 코드로 알아보기
유명한 데이터셋 중 하나인 타이타닉 데이터를 가지고 실습을 해보자.
import seaborn as sns
# 타이타닉 데이터셋 불러오기
titanic = sns.load_dataset('titanic')
titanic.head()
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
random_state = 42
# 모델 학습 및 평가
def random_forest_score(data):
# 'survived' 열을 타겟 변수(y)로 설정하고, 나머지 열을 특성(X)으로 설정
X = data.drop(columns='survived') # 타겟 변수 'survived'를 제외한 특성 데이터
y = data['survived'] # 타겟 변수 'survived' 선택
# 데이터를 훈련 세트와 테스트 세트로 분리 (훈련 80%, 테스트 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=random_state)
# Random Forest 분류기 모델 생성
model = RandomForestClassifier(random_state=random_state) # 무작위성을 제어하기 위해 random_state 설정
model.fit(X_train, y_train) # 훈련 데이터를 사용하여 모델 학습
# 테스트 데이터를 사용하여 예측 수행
y_pred = model.predict(X_test) # 모델로 예측
# 예측 결과와 실제 값(y_test)을 비교하여 정확도 계산
accuracy = accuracy_score(y_test, y_pred) # 정확도 계산
return accuracy # 정확도를 반환
d82bdf97a7c80aec2c32cbf1149db50c786cbb48
accuracy = random_forest_score(titanic)
print(accuracy)
여기에 결측치 및 이상치 처리까지 더해준다면 더 높은 성능을 기대할 수 있다. 결측치 처리 방법에는 평균/중간값 등으로 채워주는 방법, 제거하는 방법 등이 있으며, 이상치 탐지 방법에는 사분위수(IQR), Isolation Tree, DBScan(Density Based Spatial Clustering of Applications with Noise) 등이 있다.
참고
Related Posts
| RL | 강화학습이란? |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).