AI | LLM(Large Language Model)은 어떻게 답변을 생성하는 걸까?
ChatGPT, Gemini, Claude와 같은 LLM(Large Language Model)은 사람의 질문을 이해하고 꽤 자연스러운 답변을 생성한다.
최근의 LLM 서비스는 사람처럼 생각을 단계적으로 정리해 설명하고, Agent 형태로 외부 도구를 호출하거나 검색·요약·추론을 결합해 복잡한 질문에도 대응한다.
A Survey of Large Language Models (~2025.03) < 이미지 출처
나 역시 자연스러운 글을 쓸 때는 ChatGPT, 코드를 작성할 때는 Claude, 이미지를 만들 때는 Gemini, 검색을 체계적으로 하고 싶을 때는 Perplexity를 사용한다.
이런 모습을 보면 정말로 사람처럼 이해하고 사고하는 건가라는 생각이 들기도 한다. 하지만 이런 자연스러운 응답 뒤에는 우리가 쉽게 보지 못하는 명확한 계산 구조가 존재한다. LLM은 생각하거나 이해하는 존재라기보다는 수학적으로 정의된 규칙에 따라 다음 단어를 예측하는 모델에 가깝다고 할 수 있다.
그렇다면 LLM은 실제로 어떻게 질문을 처리하고, 답변을 만들어내는 걸까?
이번 글에서는 다음 내용을 중심으로 요즘 핫한 LLM의 내부 동작을 정리해보려 한다.
👉 LLM 작동 원리와 학습 방식
👉 LLM이 답변을 생성하는 단계별 과정
👉 같은 질문에도 답이 달라지는 이유
👉 프롬프트와 할루시네이션 문제
LLM이란
LLM(Large Language Model)은 대규모 언어 모델을 의미한다. 말 그대로 방대한 텍스트 데이터를 학습해 인간의 언어 패턴을 모델링한 딥러닝 모델이다.
우리가 LLM에 질문을 던지면 그럴듯한 답변을 내놓으니 당연히 이해하고 답변을 하는구나 생각하기 마련이다. LLM은 문장의 의미를 해석해 답변을 생성한다기보다는 주어진 문맥에서 다음에 올 토큰을 확률적으로 예측하며 문장을 만들어낸다.
그럼에도 불구하고 LLM의 출력이 자연스러운 이유는, 대규모 데이터에서 언어의 구조와 관계를 학습했고 문맥 전체를 고려해 확률적으로 가장 적절한 다음 토큰을 선택하기 때문이다.
즉, 의미 이해보다 고차원 확률 공간에서의 정교한 예측 결과에 가깝다.
LLM의 작동 원리
LLM은 Transformer 구조를 기반으로 하지만 번역 모델과 같은 Encoder–Decoder 구조를 그대로 사용하지 않는다. 대부분의 LLM은 Encoder를 제거한 Decoder-only Transformer 구조를 채택한다.
LLM의 목표는 다음과 같다.
“이전까지의 토큰들을 바탕으로 다음 토큰을 예측한다”
입력과 출력이 분리되지 않고, 질문 + 지금까지의 답변(이전 출력) 까지 모두 하나의 긴 시퀀스로 묶어 처리한다. 이 과정에서 모델은 Masked Self-Attention을 통해 미래 토큰은 보지 않고, 오직 이전 문맥만 참고해 다음 토큰을 예측한다.
이제 이 구조 위에서 입력이 실제로 어떻게 처리되는지를 단계별로 살펴보자.
1️⃣ 텍스트 → 토큰(Token)
자연어로 된 입력 문장은 컴퓨터가 이해하고 계산할 수 없다. 그렇기 때문에 LLM은 입력된 문장을 토큰(Token) 단위로 쪼갠다. 여기서 토큰은 단어일 수도 있고, 단어의 일부(subword)나 기호일 수도 있다.
예를 들어, “LLM은 어떻게 답변을 생성할까?”라는 문장이 있으면 다음과 같이 쪼개질 수 있다.
["LLM", "은", " 어떻게", " 답변", "을", " 생성", "할까", "?"]
2️⃣ 토큰 → 임베딩(Embedding)
입력 시퀀스를 토큰 단위로 나누었으면, 각 토큰을 이해할 수 있도록 숫자로 변환하는 과정을 임베딩이라고 한다. 각 토큰은 고정된 차원의 벡터, 즉 임베딩으로 변환된다. 이때 임베딩 벡터는 단어의 의미, 사용되는 맥락, 다른 단어와의 관계를 반영하도록 학습되었다. 실제로 Hugging Face 에는 한국어 특화 임베딩 모델도 다수 공개되어 있다.
임베딩 단계 이후부터는 텍스트가 아니라 벡터 공간에서 연산을 수행한다.
3️⃣ 문맥을 반영한 내부 표현 생성
임베딩된 토큰 벡터들은 LLM 내부의 Decoder 블록을 여러 층 통과하며 점점 더 문맥이 반영된 표현으로 변환된다.
각 Decoder 블록은 보통 아래 요소로 구성된다.
- Masked Self-Attention
- Feed Forward Network (FFN)
- Residual Connection + Layer Normalization
이 중 가장 중요한 역할을 하는 것이 Masked Self-Attention이다.
Masked Self-Attention
Self-Attention은 각 토큰이 문장 안의 다른 토큰들을 참고해 “지금 나에게 중요한 정보가 무엇인지”를 판단하는 메커니즘이다. 예를 들어 “은행에서 이상거래를 막으려면?”이라는 문장에서, “이상거래”, “막으려면” 같은 단어가 중요한 힌트가 될 수 있다.
여기에 Masked 가 붙으면 규칙이 하나 추가된다. 현재 위치의 토큰은 자기보다 뒤(미래)의 토큰을 볼 수 없고, 오직 앞(과거)의 토큰만 참고할 수 있다. 그래서 모델은 왼쪽에서 오른쪽으로 순차적으로 텍스트를 생성할 수 있다.
이 과정을 거치며 각 토큰은 문맥이 반영된 내부 표현(hidden state)으로 정제된다. 이 hidden state는 어떤 정보에 주목해야 하는지, 현재 문맥에서 무엇을 참고해야 하는지가 반영되어 있다.
Positional Encoding
Self-Attention은 기본적으로 토큰 간 유사도만으로 관계를 계산하기 때문에 토큰들의 순서를 기본적으로 모른다. 그러나 자연어에서는 단어의 순서가 중요한 역할을 하기 때문에 위치 정보를 반영하는 장치가 필요하다.
최근 LLM은 RoPE 같은 상대적 위치 인코딩을 사용해 긴 문맥에서도 안정적인 학습과 추론이 가능하도록 구현되고 있다고 한다. RoPE는 포지셔널(Positional) 정보를 임베딩에 더하는 게 아니라 Attention 계산 내부에서 Q, K에 적용한다.
여러 Decoder 블록을 통과한 뒤, 각 토큰은 충분히 문맥이 반영된 상태가 된다. LLM은 이 중 마지막 토큰의 표현을 사용해 다음 토큰이 될 확률 분포를 계산한다.
4️⃣ 확률 분포에서 다음 토큰 선택
챗봇 서비스를 이용해 본 사람들이라면 알겠지만 LLM의 출력은 항상 같지 않다. 아무리 같은 질문이라도 다시 돌리면 완전히 같은 답변이 나오는 게 아니란 말이다.
LLM의 출력은 정답 하나가 아니라, 다음 토큰 후보들에 대한 확률 분포다.
구름 한 점 없는 걸 보니, 오늘은 - 놀러가기 좋겠다! (0.87) - 비가 내리겠다. 우산을 챙겨! (0.03)
LLM은 이 분포를 바탕으로 하나의 토큰을 선택하고, 이를 다시 입력 시퀀스에 추가해 같은 과정을 반복한다. 이렇게 해서 답변은 한 토큰씩(auto-regressive) 생성된다.
LLM의 학습 방식
LLM 학습은 크게 사전 학습(Pre-training) 과 조정(Fine-tuning + Alignment) 단계로 나뉜다. 사전 학습에서 모델은 말이 되는 문장을 만들 수 있는 언어 능력을 얻고, 조정 단계에서 사용자의 의도에 맞게, 안전하고 유용하게 답하도록 행동이 다듬어진다.
Pre-training: 대규모 데이터로 무엇을 배우는가
사전 학습(Pre-training) 단계에서 LLM은 인터넷 문서, 책, 기사 등 방대한 텍스트 데이터를 통해 학습된다. 이 과정에서 모델은 문법 구조, 표현 방식, 단어 간 통계적 관계 같은 언어의 일반적인 패턴을 습득한다.
Fine-tuning: 태스크에 맞게 어떻게 조정되는가
사전 학습만으로도 문장은 잘 만들지만, 사용자 질문에 유용하게 답하는 건 별개의 문제다. 그래서 미세 조정(Fine-tuning) 단계에서는 질의응답, 대화, 요약, 도구 호출 등 원하는 사용 형태에 맞춘 데이터로 모델을 추가로 학습시킨다.
미세 조정(Fine-tuning) 단계에서는 질의응답, 대화, 요약 등 특정 목적에 맞게 모델을 조정한다. 이 과정을 통해 LLM은 질문에 답하는 방식이나 사용자와 상호작용하는 톤을 학습하게 된다. 예를 들어, 친근한 대화 톤이나 전문적인 설명 방식 같은 응답 스타일도 이 단계에서 조정된다.
실무에서는 이 단계를 조금 더 쪼개서 설명하는 경우가 많다.
- SFT(Supervised Fine-Tuning): “질문 → 모범 답변” 쌍으로 모델이 원하는 출력 스타일을 따라가도록 학습
- Alignment(정렬) 단계: 같은 질문에도 여러 답이 가능할 때, 사람이 더 선호하는 답을 선택하도록 기준을 학습
여기서 대표적인 정렬 기법이 RLHF다. RLHF(Reinforcement Learning from Human Feedback)는 사람(또는 선호 모델)이 매긴 선호도를 바탕으로 보상 모델을 만들고, 그 보상에 맞춰 모델을 추가로 조정하는 방법이다. 이를 통해 공격적인 답변이 줄고 대화 톤 같은 서비스형 응답이 안정된다.
참고로 최근에는 RLHF 외에도 DPO(Direct Preference Optimization) 처럼 선호 데이터로 더 단순하게 정렬하는 방법도 널리 쓰인다.
매번 답이 조금씩 달라질 수 있는 이유
학습이 끝난 모델도, 실제 답변 생성은 보통 확률 분포에서 토큰을 하나씩 선택하는 과정으로 진행된다. 이때 샘플링 설정에 따라 같은 질문에도 선택되는 토큰이 달라질 수 있다.
Temperature: 높을수록 확률 분포가 평평해져(무작위성 증가) 다양한 표현이 나오기 쉬움Top-k: 확률이 높은 상위 k개 후보만 남겨 그 안에서 선택Top-p: 누적 확률이 p가 될 때까지 후보를 모아 그 안에서 선택
즉, LLM은 정답을 찾는 모델이 아니라, 가능한 후보 중 하나를 선택하는 모델이기 때문에 같은 질문에도 답변이 조금씩 달라질 수 있다.
LLM에서 프롬프트는 왜 중요한가
같은 질문이더라도 질문자가 어떤 분야에 있느냐, 어떤 수준, 맥락이 주어지느냐에 따라 답변의 방향성이 달라져야 한다.
프롬프트는 LLM에게 역할과 조건을 부여해 답변의 완성도를 높인다. 즉, 프롬프트는 LLM이 다음 토큰을 예측할 때 사용하는 조건이라고 할 수 있다. 프롬프트가 달라지면, 문맥이 달라지고 확률 분포 자체가 달라진다. 그래서 같은 질문을 날리더라도 프롬프트 구성이 다르다면 전혀 다른 답변이 나올 수 있다.
답변의 완성도를 높이기 위해 활용되는 대표적인 프롬프트 전략은 다음과 같다.
- 역할(Role) 부여
- 출력 형식 명시
- 단계별로 설명해라
- 예시를 포함해라
- Context 함께 제공
- 독자의 수준, 사용 목적, 전제 조건
- Few-shot prompting
- 원하는 답변 예시를 먼저 보여준 뒤 같은 형식으로 답변 유도
할루시네이션 (Hallucination)
LLM이 사실과 다른 내용을 그럴듯하게 생성하는 현상을 할루시네이션이라고 한다.
최근에는 ChatGPT가 사람처럼 말하고 대답하다 보니, 남에게 쉽게 하지 못하는 이야기를 털어놓거나, 검색이 귀찮을 때 자연어 질문 하나로 정보를 얻는 경우도 많다. 이때 가장 치명적인 문제가 바로 할루시네이션이다.
LLM 그 자체로는 사실을 검증하지 않고 문맥상 자연스러운 토큰을 선택한다. 그래서 정보가 부족한 상황에서도 확률적으로 “말이 되는 문장”을 만들어낼 수 있고, 대화 흐름에 따라 사용자가 원하는 방향으로 검증 없이 답변을 생성해버릴 수도 있다.
RAG (Retrieval-Augmented Generation)
할루시네이션을 줄이기 위한 대표적인 방법이 RAG다. 한글로 번역하면 검색 증강 생성 기법이다.
쉽게 말하자면, LLM이 답변을 생성하기 전에 참고할 문서를 먼저 제공하고, 그 안에서 찾은 근거를 바탕으로 답변을 생성하도록 만드는 방식이다.
Retrieve(검색): 외부 문서(DB, 검색 결과)를 먼저 조회Augment(증강): 해당 내용을 컨텍스트(Context)로 주입Generate(생성): 그 범위 안에서만 답변 생성
이 방식은 LLM의 생성 능력에 신뢰 가능한 외부 근거를 결합함으로써, 할루시네이션 발생 가능성을 크게 줄여준다.
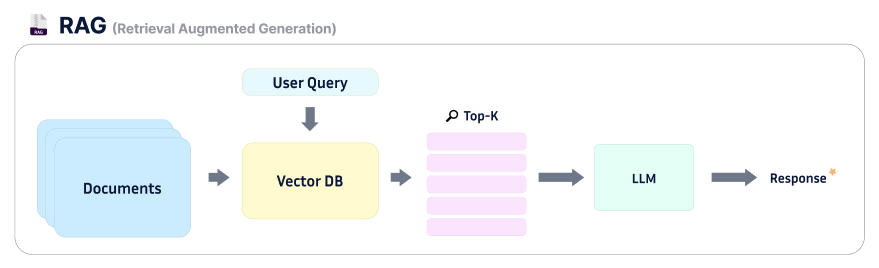
위 그림으로 간단하게 짚고 넘어가자.
우선 LLM이 참고할 문서를 Vector DB에 벡터화하여 저장해놓으면, 사용자 질문이 들어오면 이 Vector DB에서 가장 유사도가 높은 내용을 기반으로 답변을 생성하게 되는 것이다.
RAG는 보통 “검색 → 컨텍스트 주입 → 생성”으로 이루어진 파이프라인 패턴이며, 이를 빠르게 구성하기 위해 LangChain 같은 오케스트레이션 프레임워크를 활용할 수 있다.
LangChain
LangChain은 LLM 애플리케이션을 만들 때 필요한 모델, 프롬프트, Retriever, 벡터 스토어(Vector store) 같은 구성 요소를 연결·관리할 수 있도록 돕는 오케스트레이션 프레임워크다. RAG 관점에서는 문서 로딩 → 청크 분할 → 임베딩 → 검색 → 프롬프트 구성 → LLM 호출 흐름을 체인 형태로 빠르게 만들 수 있다.
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
loader = TextLoader('data.txt')
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever()
)
result = rag_chain.run("LangChain을 설명해주세요.")
print(result)
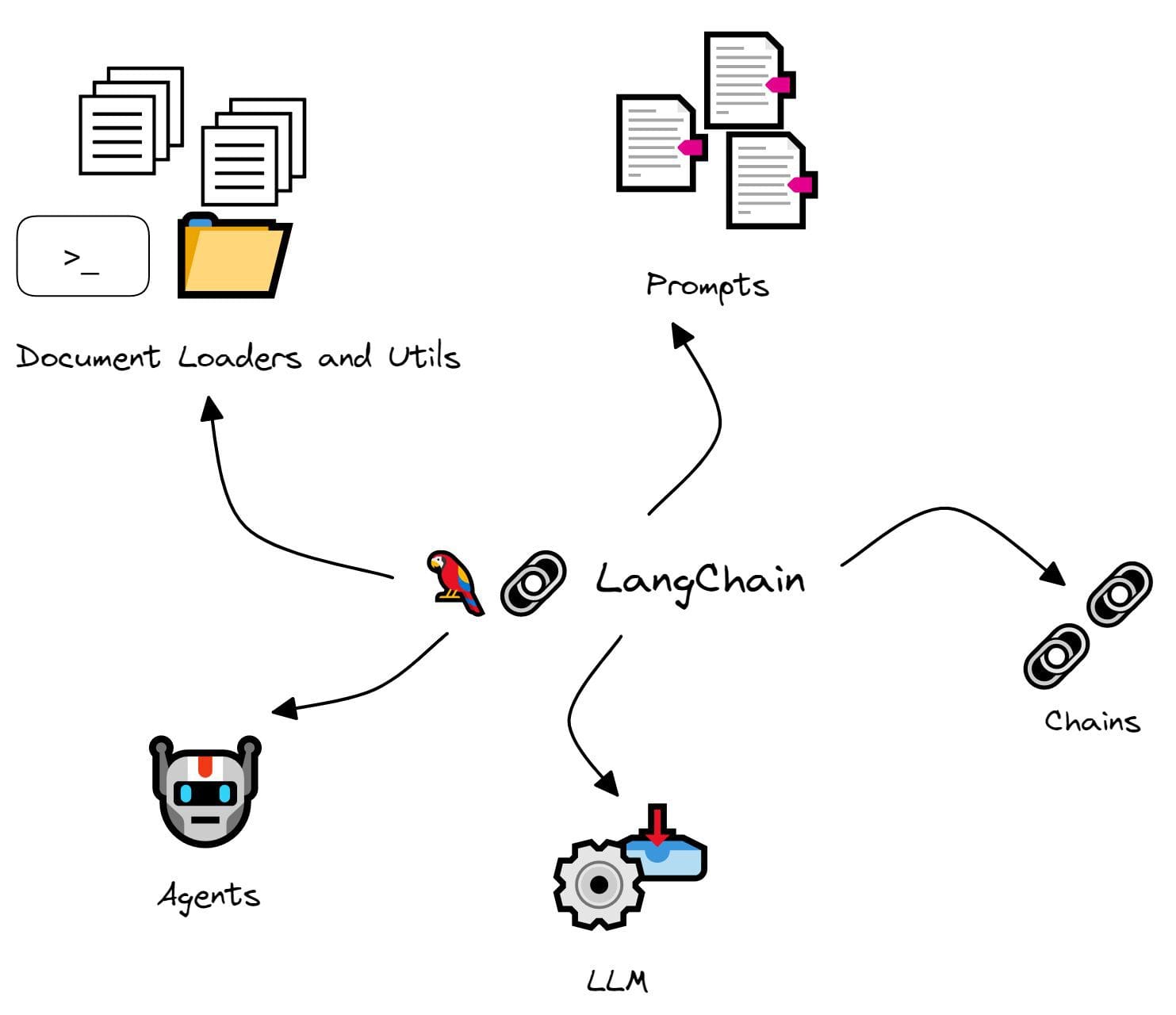
LangGraph
LangGraph는 상태(state)와 분기/루프가 있는 stateful 워크플로우·에이전트 실행을 그래프 형태로 구조화하기 위한 저수준 오케스트레이션 프레임워크다. LangChain을 사용하다 보면 한 번의 생성 실패가 전체 파이프라인 실패로 이어지거나, 분기/루프/재시도 같은 제어 로직이 복잡해지는 경우가 있는데, LangGraph는 이런 흐름을 그래프 구조로 명시적으로 표현하고 실행할 수 있게 해준다.
다만 RAG 역시 만능은 아니다. 검색 단계에서 관련 문서를 찾지 못하면 LLM은 여전히 부정확한 답변을 생성할 수 있다. 그래서 실제 서비스에서는 RAG에 출력 검증과 fallback 응답을 함께 설계하는 경우가 많다.
마무리
여기까지 LLM의 작동 원리와 학습 방식을 간단히 정리해보았다. 최근에 프롬프트를 더 정교화하고 원하는 형식대로, 신뢰도 높은 답변을 받기 위해 다양한 방법론과 라이브러리들이 제안되고 있는 것으로 알고 있다. 다음엔 이 부분에 대해서도 공부하고 정리해보겠습니다 - !
혹시 잘못된 내용이 있거나 더 궁금한 점이 있다면, 아래 댓글이나 메일로 편하게 알려주세요!

참고
Related Posts
| AI | 트랜스포머(Transformer) 쉽게 이해하기 | |
| 빅데이터 | 특성 추출 Feature Extraction | |
| 빅데이터 | 특성 선택 Feature Selection |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).