BigQuery 활용하기 (성능 최적화, 인덱스, SQL문 검증 및 실행까지!)
이번에 구글코리아 기업연계 프로젝트로 LLM 기반 데이터 분석 엔진을 개발하면서 Google Cloud의 BigQuery를 사용했다. 이 과정에서 BigQuery를 어떻게 활용했는지, 특히 성능 최적화, 유사 인덱싱 전략, SQL 실행 및 검증 흐름 그 전체적인 과정에 대해 적어보고자 한다!
➿ ➿ ➿
📌 BigQuery란?
BigQuery는 Google Cloud에서 제공하는 완전관리형 Serverless 데이터 웨어하우스입니다.

SQL 기반의 인터페이스를 통해 페타바이트(PB) 단위의 대용량 데이터를 빠르게 분석할 수 있도록 설계된 플랫폼으로, 구글 클라우드가 대신 처리해주는 초고속 분석 도구다.
❓ 왜 BigQuery여야 했나요?
GCP에는 BigQuery 외에도 Cloud SQL, Cloud Spanner 등 여러 RDB를 제공하고 있다. 그럼에도 이번에 BigQuery를 쓴 이유는 다음과 같다.
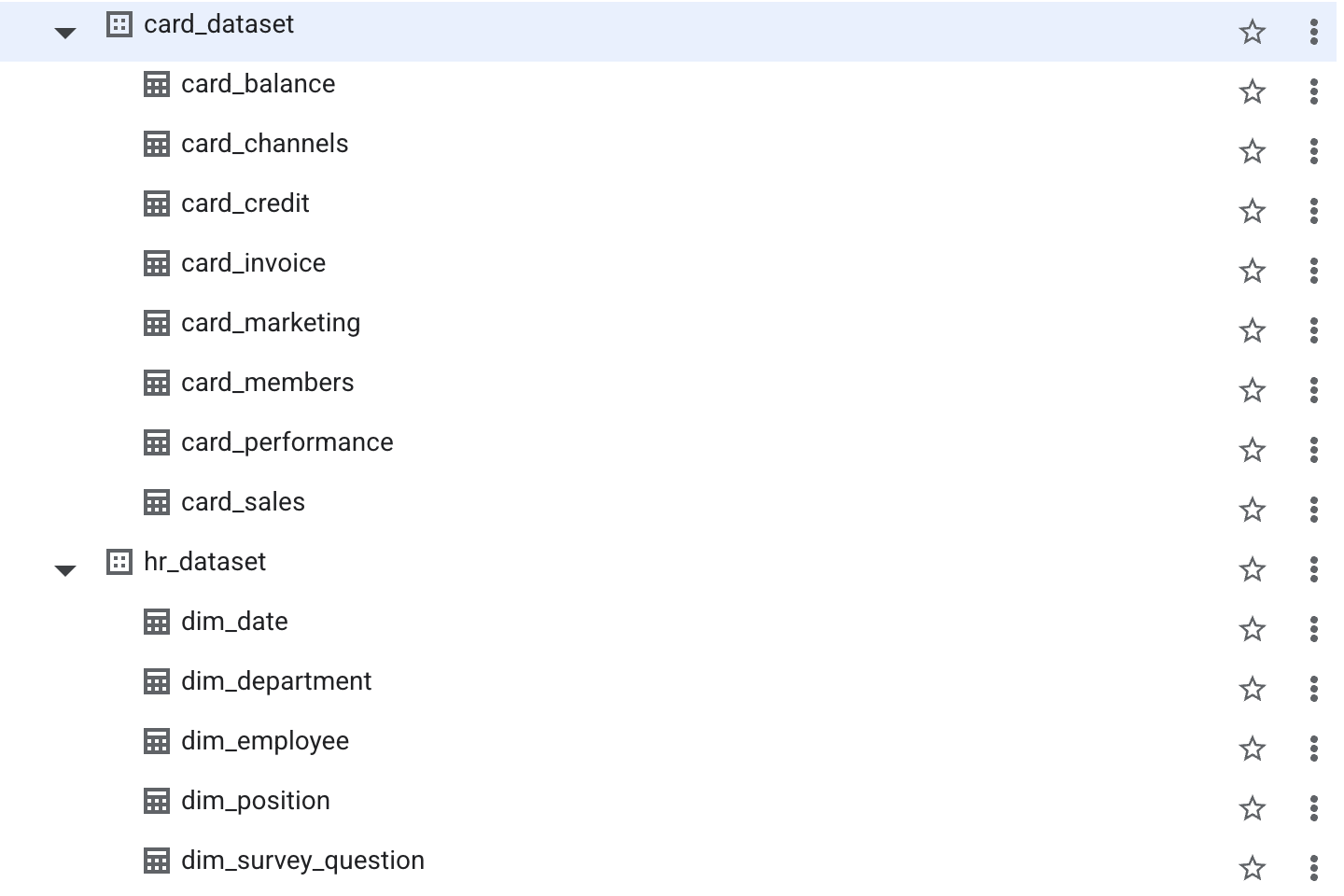
우리가 사용하는 사내 데이터는 약 300만 개의 행으로 이루어진 8개의 테이블, 그리고 각각의 테이블은 50 ~ 430개의 컬럼으로 이루어졌다. 이러한 대규모 분석에 대응해야했기 때문에 분산병렬 처리 기반으로 TB/PB 데이터도 몇 초내에 분석할 수 있는 BigQuery를 사용했다. 또한, 우리 프로젝트에 맞게 LLM이 생성하는 동적 SQL를 유연하게 처리할 수 있으며, 쿼리 단위 요금제라 다른 RDB보다 경제적이고 적합하다고 판단했다.
💡 BigQuery 인덱스 없어요!
이거 진짜에요? 일반적인 RDBMS (MySQL, PostgreSQL)는 INTEGER 컬럼에 대해 자동 인덱스(B-Tree)가 있어 빠른데, BigQuery는 명시적인 인덱스를 지원하지 않는다. 인덱스가 없기 때문에 정수든 문자열이든 스캔 범위를 줄일 구조가 없으면 무조건 느리게 조회될 수밖에 없다.
그래서 실제로 해봤을 때 데이터가 수백만 개 이상이 넘어가는 경우, 기본적인 WHERE문 조회 쿼리 실행도 8분 이상으로 매우 오래 걸렸다.
그럼에도 다음 전략을 통해 유사한 효과를 볼 수 있다.
| 전통적 인덱스 개념 | BigQuery의 대안 |
|---|---|
| B-Tree Index | Partition + Clustering |
| Bitmap Index | 고유값이 적은 컬럼을 Cluster key로 설정 |
| Composite Index | PARTITION + CLUSTER의 조합 사용 |
🌿 성능 최적화
BigQuery는 기본적으로 데이터 처리 능력이 뛰어난 데이터 웨어하우스지만, 쿼리를 어떻게 작성하냐에 따라 성능이 달라집니다.
파티셔닝 Partitioning
파티셔닝은 테이블을 특정 컬럼 기준으로 물리적으로 나눠서 저장하는 기능이다. 즉, 한 테이블을 수많은 작은 단위(partition)로 쪼개 저장함으로써, 쿼리 시 필요한 파티션만 읽어 성능과 비용을 줄이는 방법이다.
✅ 예: 날짜 기반 파티셔닝
예를 들어, 거래 테이블에서 event_date를 기준으로 파티셔닝을 설정하면 다음과 같이 쿼리를 작성할 수 있다.
CREATE TABLE my_dataset.sales_partitioned
PARTITION BY DATE(event_date)
AS SELECT * FROM raw_sales;
이렇게 생성된 테이블은 내부적으로 일자 단위로 분할 저장된다.
┌──────────────────────────────┐
│ Partition: 2024-01-01 │
│ Partition: 2024-01-02 │
│ Partition: 2024-01-03 │
│ ... │
└──────────────────────────────┘
다음부터 쿼리를 날릴 때 해당 파티션만 읽으면 되므로, 성능이 획기적으로 향상된다.
SELECT * FROM sales_partitioned
WHERE DATE(event_date) = '2024-01-02'
❎ 파티셔닝이 없으면?
SELECT * FROM sales
WHERE DATE(event_date) = '2024-01-02'
→ event_date가 파티션 키가 아니면 BigQuery는 전체 테이블을 읽어야 하므로,
수십 GB ~ TB 단위에서 쿼리 속도가 급격히 느려지고, 비용도 폭증하게 된다.
❇️ 파티셔닝 가능한 타입
| 파티션 타입 | 지원 컬럼 타입 | 예시 |
|---|---|---|
| 시간 기반 | DATE, DATETIME, TIMESTAMP |
거래일자, 생성일 등 |
| 정수 범위 기반 | INTEGER |
ym (예: 202401, 202402 등) |
| 수동 파티션 | _PARTITIONTIME, _PARTITIONDATE |
GCS나 스트리밍 데이터에 사용됨 |
클러스터링 Clustering
클러스터링은 BigQuery 테이블 내부에서 특정 컬럼 값 기준으로 데이터를 정렬해 저장하는 방식이다. 쉽게 말해 파티셔닝이 테이블을 나누는 것이라면, 클러스터링은 파티션 또는 테이블 내 데이터를 똑똑하게 정렬하는 것이다.
파티셔닝이 기준 필터링 느낌이었다면, 클러스터링은 자주 조회되는 키에 대한 빠른 검색을 위한 것이라고 생각하면 된다.
✅ 어떻게 동작할까?
CREATE TABLE clustered_table
PARTITION BY DATE(transaction_date)
CLUSTER BY user_id, card_type
AS SELECT * FROM raw_table;
이렇게 설정하면 transaction_date 단위로 파티션을 나누고, 각 파티션 안에서 user_id, card_type 순서로 데이터를 정렬하여 저장한다.
BigQuery는 쿼리를 실행할 때, WHERE 절의 조건이 클러스터링 키와 일치하거나 포함되면 → 해당 범위에 딱 필요한 블록만 읽는다 (block pruning).
✅ 예시
SELECT * FROM clustered_table
WHERE user_id = 'U123456';
클러스터링이 없으면 전체 파티션을 모두 스캔하지만, 클러스터링을 지정하면 user_id='U123456'이 위치한 블록만 읽음으로써 속도를 향상시킬 수 있다.
✅ 클러스터링 vs 파티셔닝
| 구분 | 파티셔닝 | 클러스터링 |
|---|---|---|
| 단위 | 테이블을 여러 물리적 파티션으로 분할 | 각 파티션 내부에서 정렬 및 그룹화 |
| 키 개수 | 1개만 가능 | 최대 4개까지 가능 |
| 데이터 정렬 | X | O (블록 단위 정렬) |
| 사용 목적 | 날짜나 범위 기준 필터링에 적합 | 자주 조회되는 키에 대한 빠른 검색 |
| 비용 | 없음 | 없음 (하지만 클러스터링 정렬 시 약간의 연산 부하 존재) |
검색 색인 SEARCH INDEX
비정형 문자열 검색 최적화
Search Index는 BigQuery에서 2023년부터 지원하기 시작한 문자열 전용 인덱스 기능이라고 한다. 텍스트 컬럼에 대해 역색인(inverted index)을 생성하여, 문자열 검색을 빠르게 수행할 수 있도록 최적화되었다.
기존에는 LIKE, REGEXP_CONTAINS, CONTAINS_SUBSTR 같은 문자열 검색이 전체 테이블 스캔을 유발했지만, Search Index를 사용하면 문자열 조건도 빠르게 처리할 수 있다.
✅ 생성 방법
CREATE SEARCH INDEX idx_job_mon_str
ON `my_dataset.card_members`(job_mon_str);
- 생성 대상 컬럼은 STRING 타입이어야 하며, 정수(INTEGER) 컬럼에는 적용할 수 없다.
- 테이블이 파티셔닝되어 있다면, 각 파티션에 대해 자동으로 인덱스가 생성된다.
✅ 언제 SEARCH INDEX를 써야 할까?
- 텍스트 검색이 빈번한 경우
- 특정 패턴/키워드 검색
- 정확한 값 매칭이지만 클러스터링/파티셔닝이 불가할 경우
🚀 쿼리 실행 속도를 8분에서 4초로!
우리 데이터셋은 클러스터링이나 파티셔닝을 적용해도 각 데이터가 300만 이상의 행으로 이루어져 있었기 때문에 극적인 속도 개선을 보기 어려웠다.
✨ 해결방법: STRING 변환 + Search Index
일반적인 SQL에서는 WHERE job_mon = 200012 같은 조건은 빠르게 수행된다. 하지만 BigQuery는 전통적인 인덱스가 존재하지 않기 때문에 해당 컬럼이 파티셔닝이나 클러스터링되어 있지 않다면 등호 조건도 전체 테이블을 스캔해 쿼리 조회 속도가 매우 느려진다.
이 때문에 INTEGER 타입이었던 job_mon을 STRING으로 변환하고 SEARCH INDEX를 적용했다. 그 결과 기존 8분 이상 걸리던 쿼리가 4초 만에 응답되는 극적인 속도 개선을 경험할 수 있었다.
🚗 SQL문 검증 및 실행
아래 코드는 이번 프로젝트를 진행하면서 실제로 작성하고 실행했던 코드다. 참고한다면 빠르게 실습해볼 수 있다!!
이 모든 게 가능하려면 BigQuery에 데이터셋을 올려놓고, 개인키를 발급받아 credentials.json를 다운받는 작업이 선행되어야 한다. SECRET_KEY는 항상 노출되지 않도록 .env 파일에 넣어 관리하자!
import os
import logging
from config.settings import settings
from google.cloud import bigquery
from google.oauth2 import service_account
class SQLExecutor:
def __init__(self):
credentials_path = settings.GOOGLE_APPLICATION_CREDENTIALS
if credentials_path:
if os.path.exists(credentials_path):
credentials = service_account.Credentials.from_service_account_file(
credentials_path,
scopes=[
"https://www.googleapis.com/auth/cloud-platform",
"https://www.googleapis.com/auth/drive",
"https://www.googleapis.com/auth/bigquery"
])
self.bq_client = bigquery.Client(credentials=credentials, project=settings.GOOGLE_CLOUD_PROJECT)
else:
self.bq_client = bigquery.Client(project=settings.GOOGLE_CLOUD_PROJECT)
def validate(self, query: str, location: str = "asia-northeast3"):
job_config = bigquery.QueryJobConfig(dry_run=True, use_query_cache=False)
logging.info("🔍 SQL 유효성 검사(dry run) 수행 중...")
self.bq_client.query(query, job_config=job_config, location=location)
def execute(self, query: str, location: str = "asia-northeast3"):
try:
logging.info(f"🚀 SQL 실행 시도...")
return self.bq_client.query(query, location=location).to_dataframe()
except Exception as e:
logging.warning(f"❌ SQL 실행 실패: {e}")
return None
def execute_with_retry(self, query: str, retry: int = 3):
for i in range(retry):
result = self.execute(query)
if result is not None:
return result
raise RuntimeError("모든 SQL 실행 시도 실패")
def run_bigquery(query):
try:
executor = SQLExecutor()
df = executor.execute(query)
if df is None:
logging.warning("⚠️ SQL 실행 결과가 없거나 쿼리 실패로 인해 None 반환됨.")
raise RuntimeError("SQL 실행 결과가 없습니다.")
return {
"sql_query": query,
"data": df.to_dict(orient="records") if df is not None else None
}
except Exception as e:
logging.exception("❌ NL2SQL 처리 실패:")
참고
Related Posts
| 개발 | AI를 빠르고 쉽게 서빙하는 방법, BentoML | |
| 구글코리아 x Project | LLM 기반 사내 데이터 분석 엔진, DBDeep | |
| NLP | 벡터 유사도 (Vector Similarity) 파헤치기 |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).