NLP | 벡터 유사도 (Vector Similarity) 파헤치기
컴퓨터는 자연어로 된 문장을 어떻게 이해할까?
자연어처리(NLP)에서 이 질문은 꽤 오래된 숙제였다. 단어와 문장은 결국 ‘의미’를 담고 있지만, 컴퓨터는 숫자만을 이해할 수 있기 때문이다.
그렇다면 컴퓨터는 어떻게 ‘비슷한 문장’을 판단할 수 있을까? 답은 바로 벡터 유사도(Vector Similarity) 에 있다.
오늘은 벡터 유사도에 대해 알아보고, 누가 물어봐도 쉽게 설명할 수 있게 하고자 내용을 정리하고자 한다!
➿ ➿ ➿
📌 자연어를 숫자로 바꾸기 : 임베딩 (Embedding)
Embedding은 단어, 문장, 이미지, 오디오 등 다양한 데이터를 수학적 벡터 형태로 변환하는 과정이다.
자연어를 왜 벡터로 바꾸어야할까? 컴퓨터는 사람과 같이 ‘언어’를 이해하지 못한다. 우리가 작성한 코드도 컴파일러가 기계어로 바꾸어주어야 그 기계어로 변환된 것을 연산해 주는 것이다. 그럼 어떻게 컴퓨터가 이해할 수 있도록 바꿀 수 있을까?
먼저, 컴퓨터가 연산할 수 있도록 텍스트를 숫자(벡터)로 바꿔야 한다. 이 과정을 임베딩(embedding) 이라고 부르며, 대표적으로 다음과 같은 방식이 있다.
- TF-IDF: 단어의 등장 빈도 기반.
- Word2Vec / GloVe: 단어의 의미 기반 분포 임베딩.
- Sentence-BERT / KoBERT: 문장 단위의 의미를 파악할 수 있는 임베딩 모델.
자연어 처리 성능은 ‘임베딩 성능’이라는 말이 있을 정도로, 자연어를 벡터로 바꾼 값이 단어의 특징이나 유사성 등 제대로 반영하지 못하면 무용지물이 있으니 잘 선택하도록 하자.
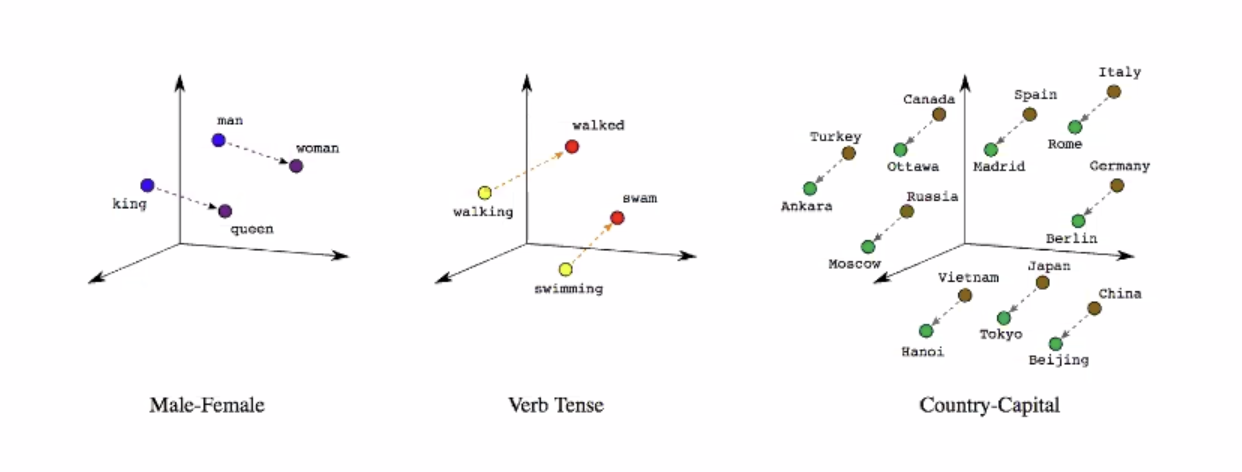
출처: 임베딩이 점이 아니라 벡터인 이유
예를 들어, “나는 오늘 커피를 마셨어” 와 “오늘은 커피를 마신 날이다” 문장 2개가 있다고 하자.
이 두 문장은 단어 배열은 다르지만 의미는 매우 유사하다. 사람은 쉽게 이해하지만, 컴퓨터는 이 문장을 수치로 바꿔 비교해야만 유사성을 판단할 수 있다.
📌 벡터 유사도란?
임베딩된 텍스트는 n차원 공간 상의 벡터이다. 특히나 비슷한 의미의 문장은 가까운 벡터 공간에 위치하도록 학습되어 있기 때문에 이 벡터들 간의 유사도를 수학적으로 계산하면, 컴퓨터도 ‘비슷하다’고 느끼게 만들 수 있는 것이다.
대표적인 유사도 측정 방법은 다음과 같다.
코사인 유사도 Cosine Similarity
두 벡터 사이의 각도를 기준으로 유사도를 계산
고등학교 벡터 시간에 배워서 다들 익숙은 할 텐데, 막상 설명해보려고 하니까 수식밖에 기억이 안 나서 애를 먹었다. 방향 유사도, 즉 의미 유사도를 보는 지표로, 간단하게 두 벡터 사이의 각도가 작을수록 유사도가 높다고 생각하면 된다!

출처: Deep-learning-free Text and Sentence Embedding, Part 1
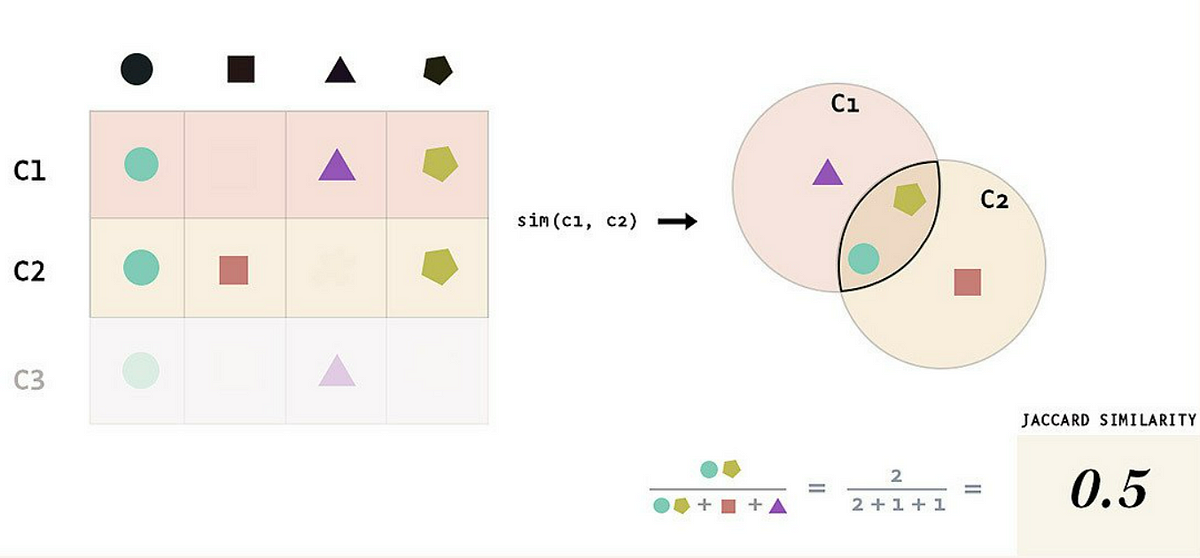
자카드 유사도 Jaccard Similarity
자카드 유사도는 두 집합 A와 B 사이의 유사성을 측정한다.
공통된 요소가 많을수록, 즉 교집합의 비율이 높을수록 유사한 집합이라고 판단한다.
유클리드 거리 Euclidean Distance
두 점 사이의 직선 거리를 말한다.
값이 작을수록 유사하고, 방향성이 아닌 ‘거리’이기 때문에 코사인 유사도처럼 방향까지 고려한 유사도보다는 의미적으로 덜 민감할 수 있다. 이해를 돕기 위한 사진을 아래에 첨부해두었다.

출처: 위키독스 | 딥러닝을 이용한 자연어 처리 입문
코사인 유사도와 비교하면 이런 느낌이라고 할 수 있겠다.
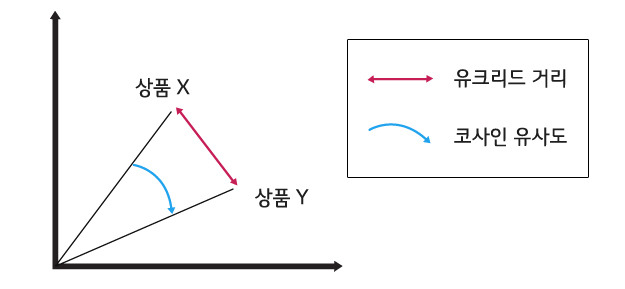
출처: 고객 시선 강탈의 중요 요소 ‘빅데이터 추천 시스템’ ①
맨해튼 거리 Manhattan Distance
각 차원에서의 차이의 합으로, 시각적으로는 격자무늬를 걷는 느낌을 생각하면 된다.
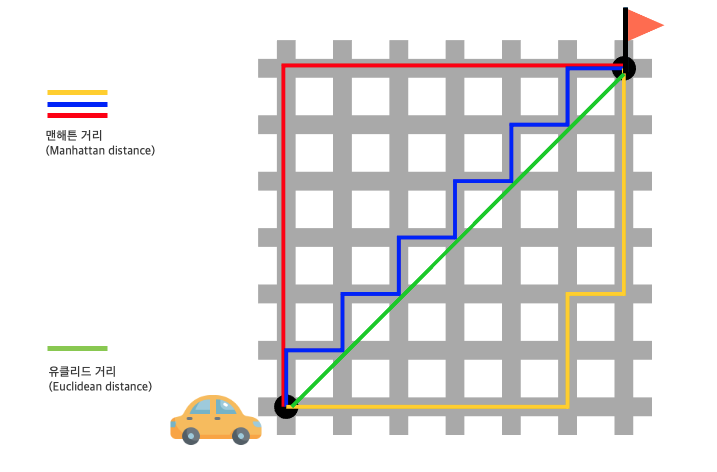
출처: 모두의 연구소
➿ ➿ ➿
🚀 마무리하며
벡터 유사도는 자연어를 수치로 바꾼 다음, 그 수치들 사이의 관계를 통해 문장의 의미 유사도를 판단하는 데 핵심 역할을 한다.
| 유사도 지표 | 잘 맞는 상황 |
|---|---|
| 코사인 유사도 | 임베딩 벡터 기반 문장/문서 의미 비교 |
| 자카드 유사도 | 토큰 기반 키워드 유사성 비교 (예: BoW, set) |
| 유클리드/맨해튼 거리 | 거리 기반 분류 모델 (KNN 등)에서 유리 |
- 코사인 유사도는 벡터의 크기는 무시하고 방향만 고려하기 때문에, 임베딩처럼 의미가 내포된 벡터 비교에 적합하다.
- 자카드 유사도는 중복을 고려하지 않고 집합 간의 순수한 겹침 정도를 판단하므로, BoW나 토큰 기반 문서 비교에 적합하다.
- 유클리드/맨해튼 거리는 각 차원 간의 거리 차이를 직접 반영하므로, 수치 기반 피처 간의 거리 비교나 KNN 분류 등에 자주 활용된다.
유사도를 비교할 땐 항상 데이터가 어떤 형태인지, 정확히 어떤 것의 유사도를 비교하고 싶은지 먼저 생각해야 한다. 유사도의 특징을 잘 기억해놨다가 상황에 적합한 유사도를 선택하도록 하자!
*BoW: 단어의 등장 여부나 빈도에만 집중해 숫자 벡터로 변환하는 방법참고
- Jaccard Similarity Made Simple: A Beginner’s Guide to Data Comparison
- NLP 자연어처리 - 한국어 임베딩
- Deep-learning-free Text and Sentence Embedding, Part 1
Related Posts
| 개발 | AI를 빠르고 쉽게 서빙하는 방법, BentoML | |
| 구글코리아 x Project | LLM 기반 사내 데이터 분석 엔진, DBDeep | |
| GCP | BigQuery 활용하기 (성능 최적화, 인덱스, SQL문 검증 및 실행까지!) |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).