Table of Contents
[ DL ] AI-OCR이란?
2023 하반기에 하나금융융합기술원 인턴으로 참여하면서 개인적으로도 열심히 공부했고 고마운 분들께 많은 것을 얻을 수 있었다. 이때 공부한 것을 여기에 조금씩 기록해 나가고자 한다.
📌 오늘의 주제 : AI-OCR
1. OCR 개념
OCR = Text detection + Text recognition
OCR Optical Character Recognition 은 광학 문자 인식으로, 이미지에 있는 글씨를 인지하여 텍스트 데이터로 치환해주는 기술을 말한다. OCR은 크게 문자 영역을 검출하는 Text detection과 검출된 영역의 문자를 인식하는 Text recognition으로 구분할 수 있다. 이 두 가지 기술을 통해 이미지 속 문자를 읽을 수 있다. 자동차 번호판 인식, 신용카드 번호 인식 등 일상생활에서도 OCR을 쉽게 찾아볼 수 있다.
Text detection은 일반적인 Object detection 중 문자를 찾아내는 태스크라고 볼 수 있다. 문자가 가지는 독특한 특성을 고려해 지속적으로 발전해 왔다고 한다.
Text recognition은 앞서 검출된 영역의 문자가 어떤 문자인지 인식해 내는 것을 말한다. 검출된 영역 속 문자가 MNIST 데이터처럼 깔끔하지 않고 다양한 각도와 형태로 존재할 수 있기 때문에 다른 모델 구조가 필요하다.
✅ AI-OCR
- 원하는 데이터만 추출하고, 이를 사람이 원하는 방식으로 가공까지 가능
- 방대한 서류를 분석하고 분류하는 데 유용
2. OCR before Deep Learning
처음부터 OCR에 딥러닝이 쓰였던 건 아니다. 보통은 아래와 같은 프로세스로 진행되었다고 한다.
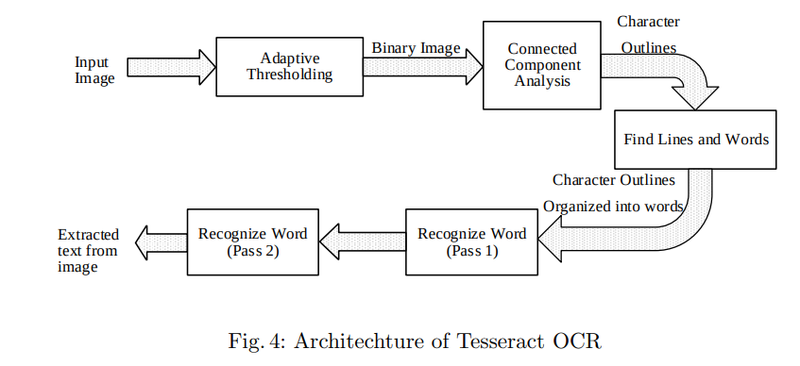
딥러닝 이전에 사용했던 OCR 엔진 중 하나로 Tesseract OCR를 간단하게 설명하자면, 아래 그림에서 Connected Component Analysis 단계에서 문자 영역을 검출한 후 Find Lines and Words 단계에서 라인 또는 단어 단위를 추출한다. 이후 Recognize Word 단계에서 단어 단위 이미지를 Text로 변환하기 위해 문자를 하나씩 인식하고 다시 결합하는 과정을 거친다.
위 방법은 필요한 단계가 많기 때문에 다소 복잡하고 시간이 오래 걸린다. 현재는 이 점 때문에 딥러닝을 적용하여 원하는 단위로 문자를 검출하고 이를 한 번에 인식하도록 아키텍처를 단순하게 하여 빠르게 OCR 인식을 하고 있다.
3. Text detection
위에서 봤듯이, 딥러닝 이전에도 OCR은 Text detection + Text recognition의 기본적인 흐름은 동일했다.
그럼 이제 딥러닝을 이용해서 Text detection 하는 법에 대해 알아보자. 이미지에서 텍스트를 찾아낼 때 단순히 object detection이나 segmentation 기법을 생각할 수 있다. 그러나 Text detection은 텍스트의 특성도 고려해 주어야 한다. 문자 하나하나가 모여 단어를 만들고, 단어가 모여 문장이 된다. 그렇기 때문에 이미지에서 문자를 검출할 때에 검출하기 위한 최소 단위를 정해야 한다는 것이다.
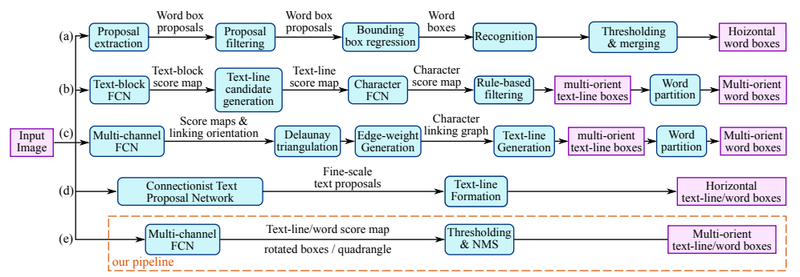
위 그림은 EAST:An Efficient and Accurate Scene Text Detector(2017) 논문에서 소개된 다양한 Text detection 기법을 정리한 것이다.
당시 detection에 있어서 주로 Text의 Bounding box를 구하는 방식에 초점을 맞추었다. 그림에서도 알 수 있듯이, 여러 방향(가로/세로/대각선 등)으로 써 있는 텍스트 박스를 구하는 방식을 다양하게 연구했다.
3.1. Text detection - Regression
TextBoxes: A Fast Text Detector with a Single Deep Neural Network
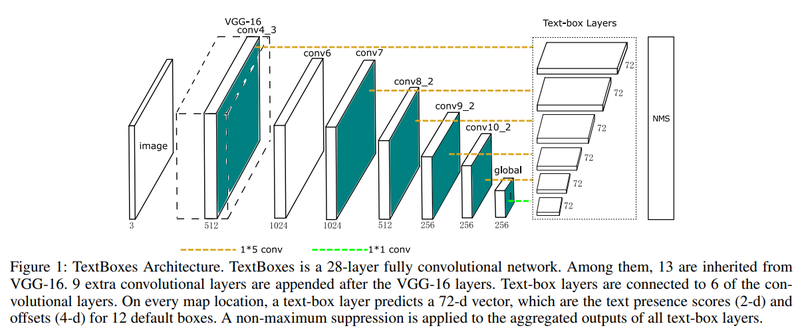
이전에는 글자 단위로 인식하여 결합하는 방식을 활용해왔다고 얘기한 바 있다. 해당 논문은 딥러닝을 활용해 단어 단위로 detection하는 법에 대해 설명한다. 네트워크 기본 구조로는 SSD: single shot multibox detector를 사용하여 빠르게 문자 영역을 탐지해내었다.
[click!] 🔎 사물 탐지 알고리즘의 일반적인 프레임워크

1️⃣ 영역 제안 (Region Proposal)
이미지에서 시스템이 처리할 영역 RoI (Regions of Interest) 를 제안하는 딥러닝 모델 또는 알고리즘을 말한다. 그리고 이때 RoI는 이미지 내 물체가 존재할 것이라 예상되는 영역을 의미한다.
2️⃣ 특징 추출 및 예측
각 박스 영역의 시각적 특징을 추출한다. 이러한 특징을 평가해서 물체 존재 여부와 클래스를 판단한다.
3️⃣ 비최대 억제 NMS, Non-Maximum Suppression
이 단계쯤이면 모델이 같은 물체에 대해 복수의 박스를 발견했을 가능성이 높다. NMS는 중복된 박스들을 탐지하고 통합하여 물체 하나마다 하나의 박스만 남도록 하는 역할을 한다.
4️⃣ 평가 지표
이미지 분류의 정확도, 정밀도, 재현율 등과 비슷하게 사물탐지에도 성능을 측정하는 고유의 평가 지표가 있다. 그 중 가장 널리 쓰이는 지표로는 평균평균정밀도 (mean average precision, MAP) 와 PR 곡선 (Precision-Recall curve), 중첩률 (Intersection over Union, IoU) 가 있다.

기존의 SSD는 Regression을 위한 Convolution layer에서 3 x 3 크기의 kernel을 갖는다. 그렇지만 단어는 일반적으로 가로로 쓰기 때문에 Aspect ratio(종횡비)가 크다는 특징이 있다. 그래서 이 논문에서는 SSD를 조금 변형해서 1 x 5 크기의 convolution filer를 정의하여 사용한다. 추가로 Anchor box의 aspect ratio를 1, 2, 3, 5, 7로 두고, 이에 vertical offset을 적용해서 세로 방향으로도 촘촘하게 배열된 단어에도 대응하도록 했다.
3.2. Text detection - Segmentation

일반적인 semantic segmentation은 이미지에서 영역을 class로 분리해낸다. 이를 문자 영역에도 적용하게 되면, 글자 부분의 영역과 배경으로 분리할 수 있다. 이때, 문자는 방향이나 각도에 따라 다르게 읽힐 수 있기 때문에 이에 관한 부분을 처리해주는 것이 중요하다.
PixelLink는 텍스트 영역을 찾아내는 segmentation과 함께, 텍스트가 어느 방향으로 연결되는지를 같이 학습하여 영역 간 분리 및 연결할 수 있는 정보를 추가적으로 활용하고 있다.
PixelLink의 전체적은 구조는 U-Net과 유사하다. 아래 아키텍처를 보면 input에서 conv 1 x 1, 2(16) 형태의 레이어가 U-Net 구조로 연결되어 output으로 함께 계산되어, 인접 pixel 간 연결 구조가 지속적으로 유지되도록 하는 모델 구조임을 알 수 있다.
output으로 Link Prediction과 Text/non-text Prediction을 가지고 있다. Text/non-text Prediction은 class segmentation map으로 해당 영역이 텍스트인지 배경인지에 대한 예측값을 의미하는 2개의 커널을 가진다. Link Prediction은 텍스트의 pixel을 중심으로 인접한 8개의 pixel에 대한 연결 여부를 의미하는 16개의 커널을 가진다고 한다.
이 과정을 거치며 인접한 pixel이 중심 pixel과 단어로 연결된 pixel인지 아닌지를 알 수 있으므로 문자 영역이 단어 단위로 분리된 Instance segmentation이 가능해진다.
3.3. Text detection - 최근
위 두 가지 regression 방식과 segmentation 방식을 적절하게 활용한 Hybrid 방식을 사용하기도 하고, 사실 최근에는 Feature extractor를 이용하는 것 같기도 하다.
4. Text Recognition
4.1. Text Recognition - RNN 계열
특히 recognition 알고리즘은 80-90년대부터 연구되오던 분야로, RNN과 Transformer 기반으로 많이 연구되었다. 그 중 시작은 RNN이었다고 한다.
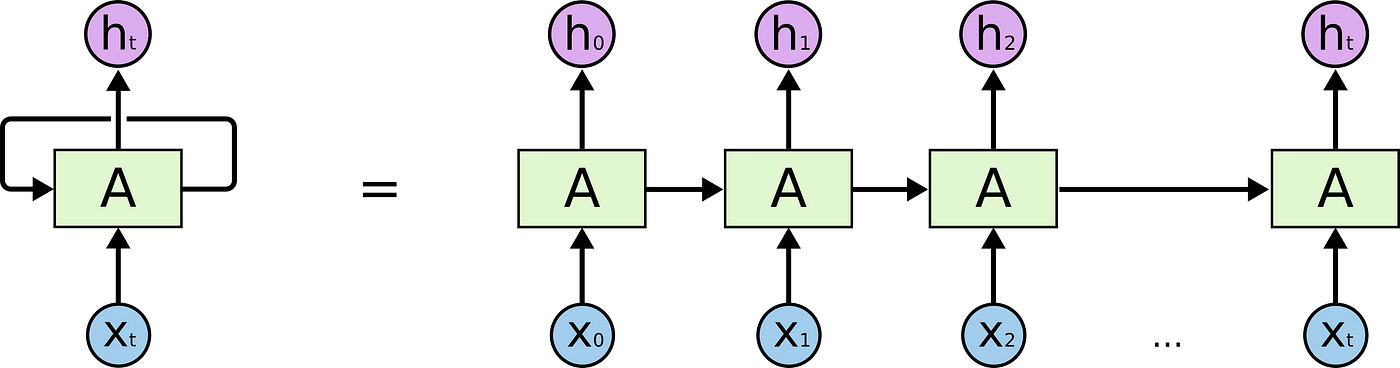
RNN(Recurrent Neural Network)의 개념을 간단히 말하자면 순환신경망 즉, 이전의 값을 참고하여 다음의 값을 추론하는 과정의 반복이다. 처음 등장했을 때는 각광 받았지만, 중간에 과정이 더해지고 복잡해질수록 오래전 값은 잊어버리는 경향이 있어 이를 극복하기 위해 LSTM(Long Short-Term Memory), GRU(Gated Recurrent Unit) 등이 등장해 성능을 높여 나갔다.
4.2. Text Recognition - Transformer 계열
2017년도에 Transformer라는 모델이 나오게 되면서 RNN 계열 기반 recognition이 완전히 바뀌게 된다. Transformer는 원래 언어 처리 분야의 언어 번역을 위해 등장한 모델 구조로, Encoder + Decoder 구조로 이루어져 있다.
Transformer는 자연어 뿐만 아니라 OCR recognition에도 아주 유능한 모델이다. OCR recognition에 적용을 하게 되면, 문자열이 아닌 이미지가 입력값으로 들어가고 출력은 동일하게 문자열이 되겠다. 여기서 핵심 모듈은 Self Attention으로, 연산되는 곳은 다음 세 가지다.

위처럼 self-attention은 Encoder에 1번, Decoder에 2번 나타난다.
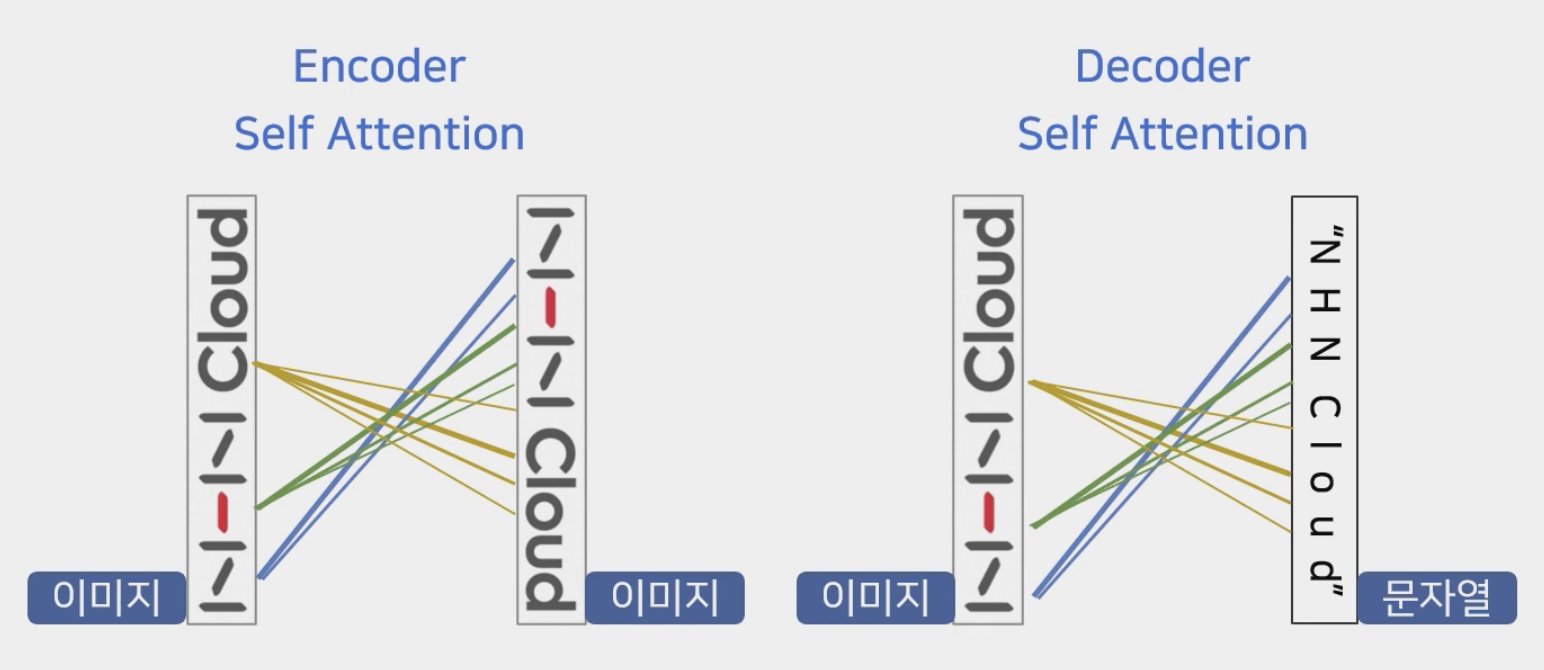
먼저, Encoder에서는 입력으로 사용된 이미지 픽셀 이미지의 관계를 모두 추론하고 특징을 추출하는 역할을 한다. 주변에 있는 픽셀에 있는 관계성이 더 높게 나타나고, 멀수록 관계성이 더 낮게 나타난다. Decoder에서의 self-attention은 입력 이미지와 최종적으로 출력할 문자열 관의 관계를 매핑시키는 역할을 한다. ‘N’이 어떤 픽셀에서 주로 나타나는지를 attention을 통해 매기고, 최종적으로 recognition 과정을 거치며 첫번째 글자가 ‘N’이라는 것을 나타낸다.
4.3. Text Recognition - 그 외
- CNN과 RNN의 만남, CRNN
- An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
- CNN 기반의 Feature Extractor + RNN 기반의 Recognition (LSTM)
- An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
- 불규칙한 방향이나 휘어진 글자의 경우
- Robust Scene Text Recognition With Automatic Rectification
- TPS : Thin Plate Spline Transformation
- Robust Scene Text Recognition With Automatic Rectification
4.4. Text Recognition - 개선 가능 방안
- 📍
Self attention: global feature extraction - 📍
Convolution module: local feature extraction
입력 이미지와 모든 픽셀을 참조하게 되는 global attention으로, Local 특징에 조금 더 집중하는 convolution과 차이가 존재한다. 그래서 local 특징에도 집중하기 위해 convolution layer를 포함한 모듈을 추가하여 개선시킬 수 있을 것이다.
혹은, Encoder의 구조를 재설계하는 방안이 있을 수도 있다. 어떤 특정 사례에서는 Self Attention을 빼고 Feature Extractor로 multi-scale을 가지는 특징을 모두 반영하고 attention의 위치를 조금 조정해서 구조를 재설계했을 때 높아지는 경우도 있었다고 말하고 있다.
5. OCR 데이터
- 오픈 데이터
- OCR 논문 연구 용도
- OCR 연구 논문 위주 사용되는 합성 데이터
- ICDAR (Challenge)
- 다양한 종류의 태스크
- 태스크별 접근 가능한 데이터
- AI Hub - 한국어 글자체 이미지
- OCR 논문 연구 용도
- 합성 데이터
- 배경 이미지, 다양한 노이즈, 폰트, 단어 사전, 휘어짐 등
Reference
Related Posts
| Summary | CNN Architectures | |
| TIL | LDA란? - NLP Topic Modeling | |
| TIL | LeakGAN이란? - NLP Text Generation Model |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).