[ NLP ] Topic Modeling : LDA , 잠재 디리클레 할당
본 포스트에서는 NLP 프로젝트를 진행하면서 공부한 내용을 정리하였다. Topic Modeling의 대표 알고리즘 LDA에 대해 알아보자.
LSA Latent Semantic Analysis
Topic Modeling 분야에 아이디어를 제공한 건 LSA 알고리즘이다. LDA를 알아보기 전에 먼저 LSA 에 대해 정리하고 넘어가자.
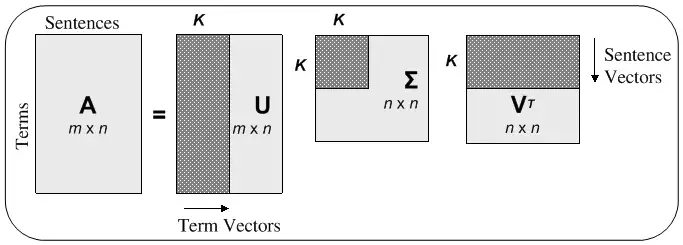
LSA는 Topic Modeling 을 위해 최적화된 알고리즘은 아니다.
그러나 기존의 BoW Bag of Words 에 기반한 DTM이나 TF-IDF 방법의 단어의 빈도수만 이용하고 의미를 고려하지 못했다는 한계점을 보완한 방법으로 DTM의 잠재된 (Latent) 의미를 분석한다고 해서 LSA 라는 알고리즘이 제안되었다. 다른 말로 LSI Latent Semantic Indexing 라고 부르기도 한다고 한다.
LSA 는 먼저 DTM 이나 TF-IDF 행렬에 절단된 SVD (truncated SVD) 를 사용해서 차원을 축소시키고, 단어들의 잠재 의미를 끌어낸다.
Truncated SVD 를 이용하여 행렬의 특이값 중 상위 t 개만 남기고 나머지는 모두 제거하여 차원을 축소한다. 이때 t 는 토픽의 개수를 의미한다. 이런식으로 나온 문서 벡터들과 단어 벡터들을 통해 다른 문서의 유사도, 다른 단어의 유사도, 단어로부터 문서의 유사도를 구할 수 있다.
LSA 를 이용하면 쉽고 빠르게 구현이 가능하며, 단어의 잠재 의미를 이끌어낼 수 있어서 좋은 성능을 보여줄 수 있다. 그러나 SVD의 특성상 이미 계산된 LSA 에 새로운 데이터가 들어오면 일반적으로 처음부터 다시 계산해야하기 때문에 LSA 대신 Word2Vec 등 단어의 의미를 벡터화하여 사용하는 인공 신경망 기반의 방법론이 주목받고 있다.
LSA 를 이용하여 토픽 모델링 실습도 해보자. 실습 코드는 아래에 적어놓았다.
LDA Latent Dirichlet Allocation
LDA 는 주어진 문서에 대하여 각 문서에 어떤 주제들이 존재하는지에 대한 확률모형으로, 토픽 모델링의 대표적인 알고리즘이다. 대략적인 구조는 다음과 같다.
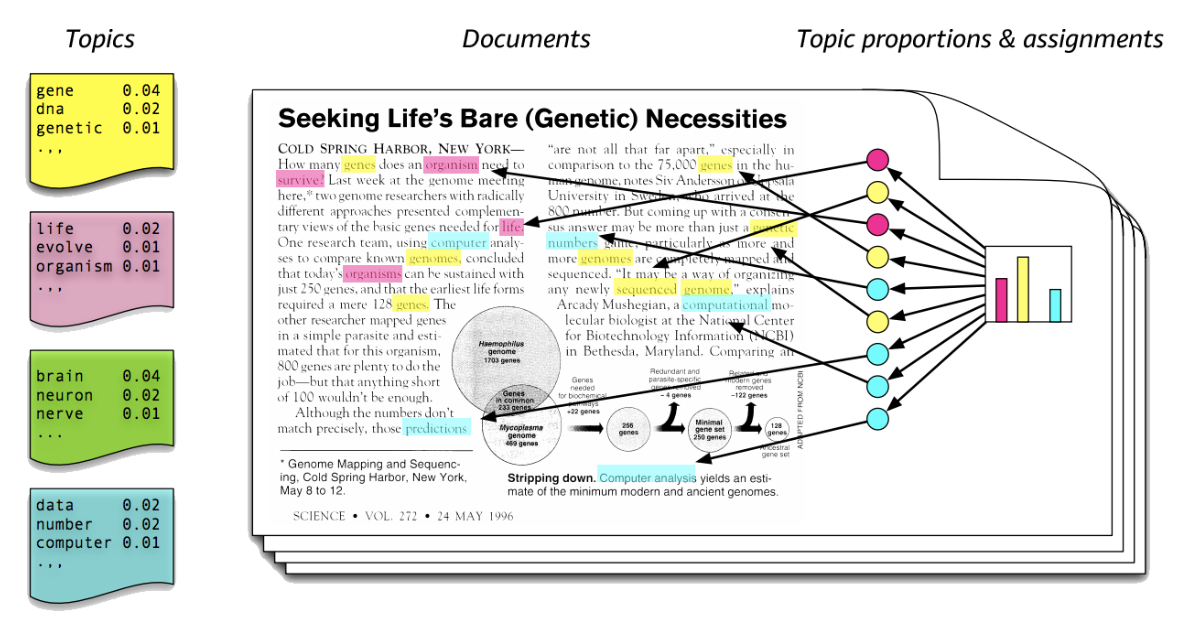
LDA 는 다음의 상황을 가정한다.
- 문서들은 토픽들의 혼합으로 구성
- 토픽들은 확률 분포에 기반하여 단어를 생성
LDA 는 특정 토픽에 특정 단어가 나타날 확률을 계산해준다. 위의 그림을 예시로 들어보자면, 노란색 토픽은 gene, dna, genetic 이라는 단어가 나올 확률이 높은 걸로 보아 유전자 관련 주제일 것이다. 한편, 문서를 보면 빨간색, 파란색 토픽에 해당하는 단어보다 노란색 토픽에 해당하는 단어가 더 많은 걸로 보아 노란색 토픽일 가능성이 높을 것이다. 이런식으로 LDA를 이용해 문서의 토픽을 추출해낸다.
⚙️ LDA 수행 과정
1️⃣ 사용자가 알고리즘에게 토픽의 개수 k 를 지정해준다.
2️⃣ 모든 단어를 k 개 중 하나의 토픽에 할당한다.
3️⃣ 모든 문서의 모든 단어에 대하여 다음 과정을 반복한다.
어떤 문서에서 각 단어 w 가 잘못된 토픽에 할당, 나머지 단어는 모두 올바른 토픽에 할당되어있다고 가정하여 다음의 2가지 기준에 따라 재할당된다.
p(topic t | document d): 문서 d의 단어들 중 토픽 t에 해당하는 단어들의 비율p(word w | topic t): 각 토픽들 t에서 해당 단어 w의 분포
LDA 를 이용하여 토픽 모델링 실습도 해보자. 마찬가지로, 실습 코드는 아래에 적어놓았다.
🤔 LSA와 LDA의 차이?
- LSA는 DTM을 차원 축소하고, 축소된 차원에서 근접 단어들을 토픽으로 묶는다.
- LDA는 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출한다.
💻 코드 실습
- LSA
scikit-learn의 Twenty Newsgroups 데이터를 이용해 LSA 실습을 진행해보자.
해당 데이터셋은 20개의 다른 주제를 가진 뉴스그룹 데이터를 포함하고 있고, 이를 이용해 문서를 원하는 토픽의 수로 압축하여 각 토픽 당 가장 중요한 단어 5개를 추출할 것이다.
참고 : Wikidocs : 잠재 의미 분석
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
import nltk
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
dataset = fetch_20newsgroups(shuffle=True, random_state=42, remove=('headers', 'footers', 'quotes'))
# 뉴스 그룹 데이터
documents = dataset.data
# 카테고리
dataset.target_names
news_df = pd.DataFrame({'document':documents})
# 특수 문자 제거
news_df['clean_doc'] = news_df['document'].str.replace("[^a-zA-Z]", " ")
# 길이가 3이하인 단어는 제거 (길이가 짧은 단어 제거)
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]))
# 전체 단어에 대한 소문자 변환
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: x.lower())
# NLTK로부터 불용어를 받아오기
stop_words = stopwords.words('english')
# 토큰화
tokenized_doc = news_df['clean_doc'].apply(lambda x: x.split())
tokenized_doc = tokenized_doc.apply(lambda x: [item for item in x if item not in stop_words])
# 역토큰화
detokenized_doc = []
for i in range(len(news_df)):
t = ' '.join(tokenized_doc[i])
detokenized_doc.append(t)
news_df['clean_doc'] = detokenized_doc
# TF-IDF
vectorizer = TfidfVectorizer(stop_words='english', max_features= 1000, # 상위 1,000개의 단어를 보존
max_df = 0.5, smooth_idf=True)
X = vectorizer.fit_transform(news_df['clean_doc'])
# Topic Modeling
svd_model = TruncatedSVD(n_components=20, algorithm='randomized', n_iter=100, random_state=122)
svd_model.fit(X)
# topic 개수
len(svd_model.components_)
- LDA
이번엔 약 15년 간 발행된 영어 뉴스 기사 제목을 모아놓은 데이터셋을 이용하여 scikit learn의 LDA 실습을 해보겠다.
참고 : Wikidocs : 사이킷런의 잠재 디리클레 할당 학습
import pandas as pd
import urllib.request
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
urllib.request.urlretrieve("https://raw.githubusercontent.com/ukairia777/tensorflow-nlp-tutorial/main/19.%20Topic%20Modeling/dataset/abcnews-date-text.csv", filename="abcnews-date-text.csv")
data = pd.read_csv('abcnews-date-text.csv', error_bad_lines=False)
# 뉴스 제목 데이터만 저장
text = data[['headline_text']]
# 불용어 제거
text['headline_text'] = text.apply(lambda row: nltk.word_tokenize(row['headline_text']), axis=1)
stop_words = stopwords.words('english')
text['headline_text'] = text['headline_text'].apply(lambda x: [word for word in x if word not in (stop_words)])
# 3인칭 단수 -> 1인칭 / 과거 현재형 -> 현재
text['headline_text'] = text['headline_text'].apply(lambda x: [WordNetLemmatizer().lemmatize(word, pos='v') for word in x])
# 길이가 3 이하인 단어는 제거
tokenized_doc = text['headline_text'].apply(lambda x: [word for word in x if len(word) > 3])
# 역토큰화 (토큰화 작업을 되돌림)
detokenized_doc = []
for i in range(len(text)):
t = ' '.join(tokenized_doc[i])
detokenized_doc.append(t)
# 다시 text['headline_text']에 재저장
text['headline_text'] = detokenized_doc
# 상위 1,000개의 단어를 보존
vectorizer = TfidfVectorizer(stop_words='english', max_features= 1000)
# TF-IDF 행렬 만들기
X = vectorizer.fit_transform(text['headline_text'])
# 토픽 모델링
lda_model = LatentDirichletAllocation(n_components=10,learning_method='online',random_state=777,max_iter=1)
lda_top = lda_model.fit_transform(X)
# 단어 집합. 1,000개의 단어가 저장됨.
terms = vectorizer.get_feature_names()
def get_topics(components, feature_names, n=5):
for idx, topic in enumerate(components):
print("Topic %d:" % (idx+1), [(feature_names[i], topic[i].round(2)) for i in topic.argsort()[:-n - 1:-1]])
get_topics(lda_model.components_,terms)
# LDA 시각화
# pip install pyLDAvis
import pyLDAvis.gensim_models
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim_models.prepare(ldamodel, corpus, dictionary)
pyLDAvis.display(vis)
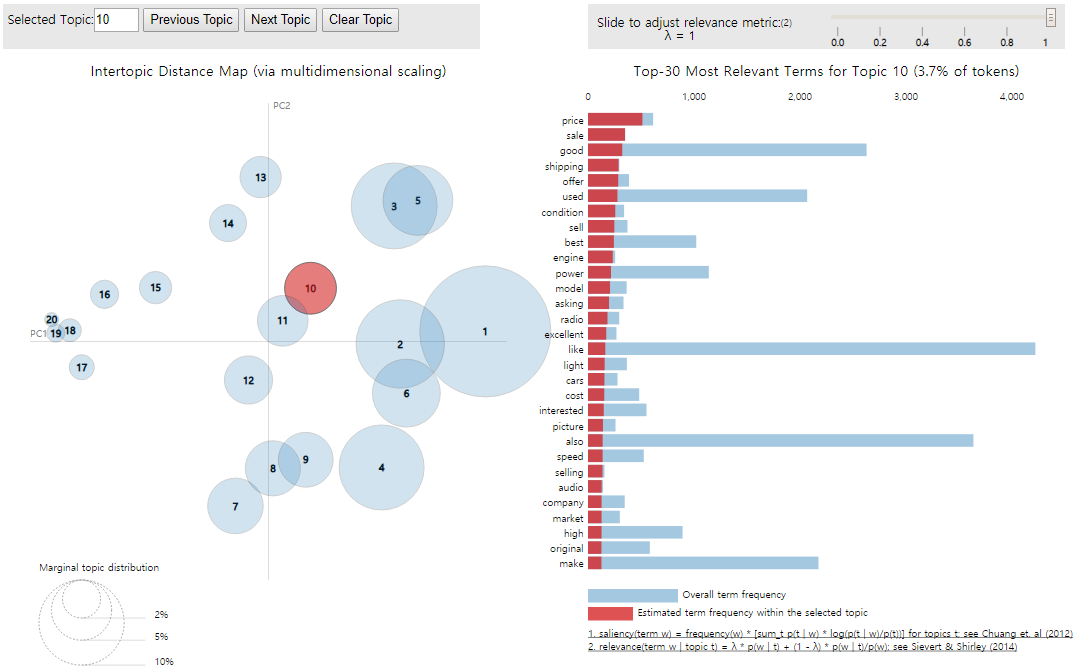
각 원과의 거리는 각 토픽들이 서로 얼마나 다른지를 보여준다. 주의해야할 점은 LDA 모델에서 출력을 하면 토픽 번호가 0부터 부여되지만, 위의 라이브러리를 이용하여 시각화를 하면 토픽 번호가 1부터 시작된다는 점이다.
# 문서 별 토픽 분포 보기
for i, topic_list in enumerate(ldamodel[corpus]):
if i==5:
break
print(i,'번째 문서의 topic 비율은',topic_list)
# 문서 별 토픽 분포 데이터 프레임으로 보기
def make_topictable_per_doc(ldamodel, corpus):
topic_table = pd.DataFrame()
for i, topic_list in enumerate(ldamodel[corpus]):
doc = topic_list[0] if ldamodel.per_word_topics else topic_list
doc = sorted(doc, key=lambda x: (x[1]), reverse=True)
# 모든 문서에 대해서 각각 아래를 수행
for j, (topic_num, prop_topic) in enumerate(doc):
if j == 0: # 가장 비중이 높은 토픽
topic_table = topic_table.append(pd.Series([int(topic_num), round(prop_topic,4), topic_list]), ignore_index=True)
else:
break
return(topic_table)
topictable = make_topictable_per_doc(ldamodel, corpus)
topictable = topictable.reset_index() # 문서 번호을 의미하는 열(column)로 사용하기 위해서 인덱스 열을 하나 더 만든다.
topictable.columns = ['문서 번호', '가장 비중이 높은 토픽', '가장 높은 토픽의 비중', '각 토픽의 비중']
topictable[:10]
참고
Wikidocs : 사이킷런의 잠재 디리클레 할당 학습
Latent Semantic Analysis — Deduce the hidden topic from the document
Related Posts
| Summary | AI-OCR란? | |
| Summary | CNN Architectures | |
| TIL | LeakGAN이란? - NLP Text Generation Model |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).