[ 빅데이터 ] 차원의 저주 (The curse of dimensionality) 란?
개념 | 차원의 저주
일반적으로 데이터를 가지고 예측 모델을 만들 때 feature가 1개일 때보다 여러 개일 때 더 정확한 모델을 만들 수 있다.
예를 들어, 한 고객의 신용등급을 예측한다고 했을 때 그 사람의 연봉만 보는 것보다 결혼 여부, 가족 구성원 수, 연체 횟수, 신용카드 등도 같이 포함해서 평가를 하는 것이 더 정확하다.
차원의 저주는 이것과 반대의 케이스이다.
차원의 저주란 데이터 학습을 위해 차원이 증가하면서 학습 데이터 수가 차원의 수보다 적어져 성능이 저하되는 현상으로, 차원이 증가할수록 개별 차원 내 학습할 데이터 수가 적어지는(sparse) 현상이 발생한다.
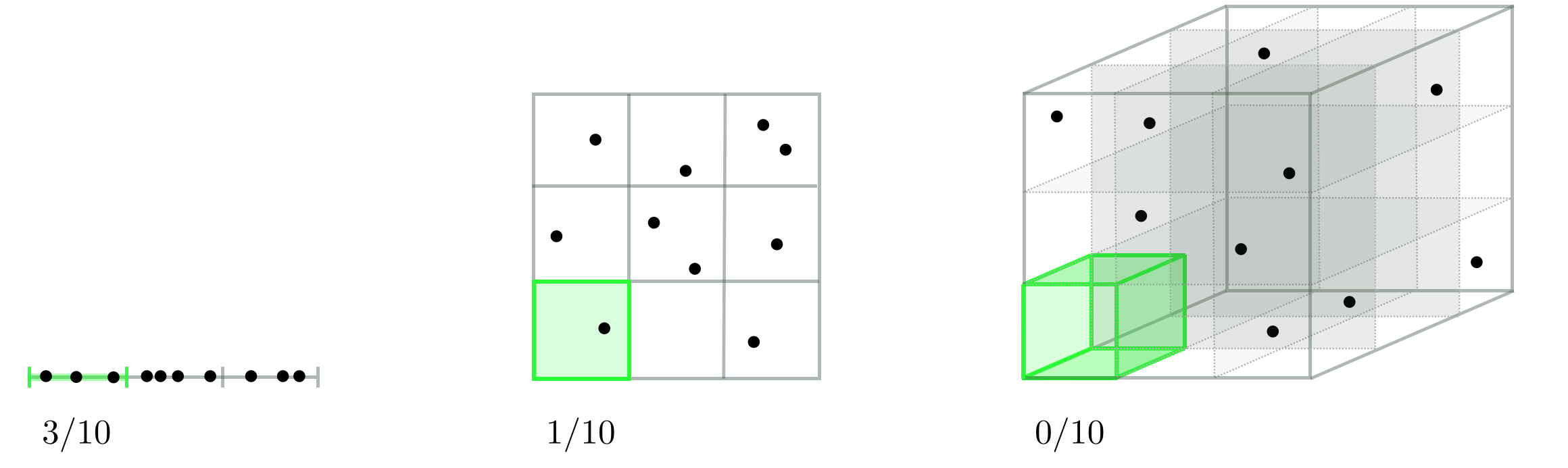
즉, 차원의 저주란 차원이 증가함에 따라 (=변수 개수 증가) 모델의 성능이 저하되는 현상이다. 단, 매번 그런 건 아니고 관측치 수보다 변수의 수가 많아질 때 이런 현상이 발생한다.
🔎 왜 성능이 저하되는 거지?
빈 공간이 생겼다 = 0
쓰지 않는 공간이 늘어난 상태(정보가 적은 상태)에서 계속 학습을 하게 되면 당연히 모델을 학습할 때 성능이 저하될 수밖에 없다. 각 차원별 충분한 데이터가 존재하지 않으니 과적합으로 이어질 위험이 있다. 또, 모델이 학습을 제대로 진행하기 위한 필요한 데이터의 양이 많아지고 이들을 계산할 때 연산 비용이 증가할 수 있다.
차원의 저주 문제에 치명적인 알고리즘이 바로 KNN 이다.
KNN K-Nearest Neighborhood 는 자신과 가장 가까운 이웃 K 개 중에서 라벨을 정하게 되는데, 차원이 커지면 내 주변 이웃이 점점 더 멀어지게 된다. 그래서 너무 큰 차원이라면 KNN 이외의 알고리즘을 쓰거나 차원을 줄이는 방법으로 데이터를 정제해야 한다.
💫 차원의 저주 해결방법
- Feature Selection
종속성이 강한 불필요한 특성 (feature) 는 제거하고, 데이터의 특징을 잘 나타내는 주요 특징만 선택하는 방법.
예를 들어, 1개월 간 강수량을 예측하는 모델을 개발한다고 가정해보자. 이 예측모델을 만들기 위해 개발자들은 다양한 지역에서 갖가지 데이터를 수집할 것이다. 기온, 습도, 인구 외 교통량이나 대형 전시·콘서트 개최 횟수도 포함될 수 있다.
이렇게 모은 정보가 모두 강우량 예측과 관련이 있는 것은 아니다. 차원의 저주에서 말하는 ‘차원’이란 이렇듯 머신러닝 모델 구축시 각 샘플을 정의하는 정보 개수를 뜻한다. 샘플이 지나치게 많을수록 복잡성은 가중되고, 머신러닝 모델을 구동하는 데에도 더 많은 전력을 소비하게 된다.
이렇게 모은 정보가 모두 강우량 예측과 관련이 있는 것은 아니다. 차원의 저주에서 말하는 ‘차원’이란 이렇듯 머신러닝 모델 구축시 각 샘플을 정의하는 정보 개수를 뜻한다. 샘플이 지나치게 많을수록 복잡성은 가중되고, 머신러닝 모델을 구동하는 데에도 더 많은 전력을 소비하게 된다.
그래서 데이터의 특징을 잘 나타내는 주요 특징만 선택하는 방법으로, 아래의 방법들이 있다. 각 방법에 대한 더 구체적인 내용은 다음 포스트에 정리할 예정이다.
Filter Method: feature 간 상관관계 파악Wrapper Method: Feature Subset의 유용성을 측정Embedded Method: Feature Subset의 유용성을 측정하지만, 내장 metric을 사용
📍 더 자세히 보러가기
[ 빅데이터 ] 특성 선택 Feature Selection - Filter / Wrapper / Embedded
- Feature Extraction
기존 특성 (feature)를 저차원의 중요 특성으로 압축하여 추출하는 것
- 주성분분석 PCA
- 비선형 차원 축소방법 t-SNE
- 선형판별분석 LDA 등
📍 더 자세히 보러가기
[ 빅데이터 ] 특성 추출 Feature Extraction - PCA / t-SNE / LDA
Reference
Related Posts
| AI | LLM(Large Language Model)은 어떻게 답변을 생성하는 걸까? | |
| AI | 트랜스포머(Transformer) 쉽게 이해하기 | |
| 빅데이터 | 특성 추출 Feature Extraction |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).