Table of Contents
Elastic Search이 대체 뭐야? (개념, 장단점, 활용예시, 실습)
최근 개발을 하면서 Elastic Search를 사용했다. 정확히 개념을 이해하고 또 다음에 필요할 때 꺼내쓰기 위해 이게 무엇인지 정리하고자 한다.
➿ ➿ ➿
🌐 Elasticsearch란
![]()
Elasticsearch는 RESTful API를 제공하며, 데이터를 실시간으로 색인하고 검색할 수 있도록 설계되어 있다.
Elasticsearch는 대용량 데이터를 빠르게 검색하고 분석할 수 있는 분산형 검색 및 분석 엔진이다.
Elasticsearch의 주요 개념
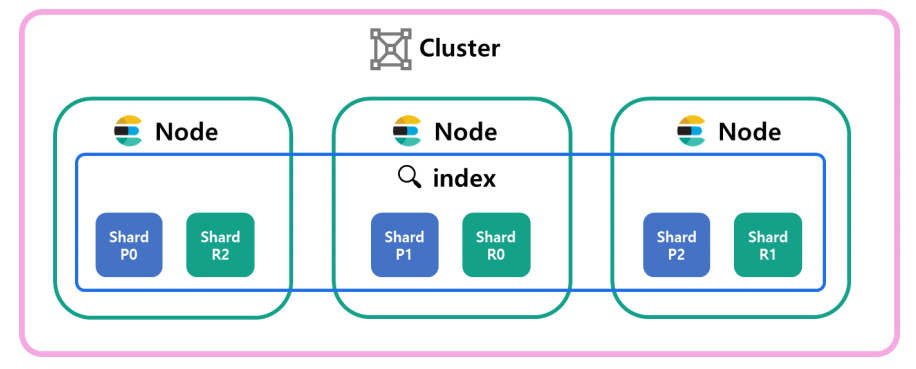
출처: elasticsearch 시작 가이드
인덱스(Index)
Elasticsearch에서 인덱스는 데이터가 저장되는 기본 단위로, 관계형 데이터베이스(RDBMS)의 테이블 의 개념과 유사하다. 각 인덱스는 문서(document)의 집합이며, 인덱스를 잘 설계해야 성능도 좋게 가져갈 수 있다.
문서(Document)
문서는 JSON 형식으로 저장되는 데이터의 최소 단위다. 각 문서에는 고유한 ID가 부여되며, 특정 인덱스 내에서 관리된다. 쉽게 말하자면, MySQL의 테이블에서 데이터 1개(row) 와 비슷하다고 생각하면 될 것 같다.
샤드(Shard)와 레플리카(Replica)
Elasticsearch는 대량의 데이터를 빠르게 검색하고 분산 저장하기 위해 샤드와 레플리카의 개념을 사용한다. 샤드는 데이터를 수평적으로 나누어 저장하는 단위, 레플레카는 해당 샤드의 복사본으로 데이터의 고가용성을 보장한다고 한다.
쉽게 말하자면 샤드는 데이터를 조각내어 저장하는 단위다. 즉, 하나의 인덱스(Index)를 여러 개의 조각(Shard)으로 나누어 저장하는 것을 말한다.
클러스터(Cluster)
Elasticsearch 클러스터란 하나 이상의 서버(노드)로 구성된 집합체다. 클러스터는 동일한 클러스터 이름으로 구성된 모든 노드를 자동으로 발견하며, 노드들과 데이터와 작업을 공유하여 이를 통해 대량의 데이터를 효율적으로 분산 처리한다. 또한 대량의 데이터 처리와 높은 병렬 처리 성능을 보장한다.
네? 아직 모르겠어요.
위의 설명을 듣고 이해가 안 됐다면 나와 비슷한 곳에서 의문점이 생겼을 듯하다.
💫 샤드를 왜 나눌까(수평 분할)?
데이터가 많아지고 이 모든 데이터를 하나의 서버(노드)에 저장하는 경우 부담이 커진다. 그래서 샤드를 나누어 여러 개의 서버(노드)에 분산 저장하면서 성능을 향상시킨다. 즉, 데이터를 수평적으로 나눈다 = 하나의 인덱스를 여러 개의 노드에 나누어 저장하여 부하를 분산한다!
💫 샤드의 복사본(레플리카)으로 어떻게 데이터의 고가용성을 보장해?
특정 샤드가 저장된 노드에 장애가 발생해도, 레플리카가 존재하면 데이터를 잃지 않을 수 있다.
=> 샤드 하나가 손실되더라도 레플리카가 대신 역할을 수행하기 때문에 안정성이 높아진다.
또한 동일한 데이터를 여러 개의 노드에서 검색할 수 있기 떄문에 검색 요청 부하가 분산된다. 레플리카가 많을수록 더 많은 요청을 병렬로 처리할 수 있다는 말이다.
Elasticsearch: 🏢 도서관
Document: 📔 책
Shard: 🗄️ 책을 보관하는 책장
Replica: 🔗 같은 책을 복사해 다른 지점 도서관에 보관
>> 화재로 인한 유실 위험에서 비교적 안전, 개별 샤드 단위로 복사
다만, 실무에서는 인덱스의 데이터 크기와 클러스터의 노드 수 등을 고려하여 샤드의 개수를 적절히 설정해야 한다. 샤드가 너무 많으면 클러스터의 오버헤드가 증가하며, 샤드가 너무 적으면 데이터 분산 및 병렬 처리 효율이 떨어지니까!
➿ ➿ ➿
🚀 그럼 Elasticsearch는 어째서 빠른 걸까?
Elasticsearch가 빠른 검색 성능을 가지는 이유는 역색인 (Inverted Index) 구조와 분산 아키텍처 덕분이다.
✅ 역색인 구조(Inverted Index)
일반적인 데이터베이스(RDBMS)는 B-Tree 또는 Hash Index 구조를 이용하지만, Elasticsearch는 역색인을 사용한다. 역색인은 문서 내의 단어(토큰)들이 어디에 위치하는지 미리 색인하는 방식으로, 검색할 때 전체 데이터를 스캔할 필요 없이 바로 원하는 결과를 찾아낼 수 있다.
- RDBMS 검색 방식 (
LIKE '%keyword%)- LIKE 검색은 전체 행을 Full Table Scan해야 하기 때문에 느림
- Elasticsearch 역색인 방식
- 만약
Hello World라는 데이터(문서)가 있다고 한다면, Elasticsearch는 다음과 같이 색인을 만듦- “Hello” -> { document1, document3, document8 }
- “World” -> { document1, document2, document5 }
- 문서 » 키워드 가 아니라 키워드 >> 문서
- 일반적으로 문서 본문 내용을 키워드로 검색해서 찾을 때 유용
- 만약
✅ 분산 저장과 병렬 처리
앞서 Elasticsearch는 데이터를 여러 개의 샤드로 나누어 저장한다고 했었다. 이는 검색할 때 모든 샤드에서 병렬로 검색을 수행하고 결과를 조합할 수 있게 하여 검색 속도를 높일 수 있다. 즉, 하나의 서버가 아니라 여러 개의 서버에서 동시에 검색하기 때문에 빠르다.
또한 Elasticsearch는 샤드의 복사본, 레플리카를 활용한다. 검색 요청이 많아지면 레플리카도 검색을 수행할 수 있도록 분산 처리를 한다고 한다. 즉, 검색 요청을 여러 개의 서버가 나누어 처리하기 때문에 부하가 분산된다.
🔮 DB와 Elasticsearch 조합
NoSQL + Elasticsearch
NoSQL에서 검색 쿼리 성능으로 높일 때 Elasticsearch를 쓴다던데…
⭕️ 사실이다!
MongoDB, DynamoDB와 같은 NoSQL은 검색 성능이 약한 편이다. NoSQL의 주요 설계 목표는 검색 보다는 데이터의 저장과 확장성에 두고 있기 때문인데, 특히 NoSQL은 일반적으로 LIKE 검색을 지원하지 않거나 느리게 동작하는 경우가 많다.
Elasticsearch를 NoSQL과 함께 사용하는 이유
NoSQL은 대량 데이터를 저장하는 데 최적화되어 있지만 검색에는 약점을 보인다. 반면 Elasticsearch는 역색인과 분산 구조로 인해 검색에 최적화되어 있어서 NoSQL + Elasticsearch 조합을 사용해서 데이터 저장과 검색을 최적화할 수 있다!
실제로 나는 이번에 계층적 문서구조를 MongoDB에 저장하면서 Elasticsearch와 함께 검색을 수행하도록 하여 검색 쿼리를 설계했었다.
관계형 데이터베이스(RDBMS) + Elasticsearch
그럼 관계형 데이터베이스에서도 Elasticsearch를 사용할까?
RDB도 Elasticsearch에 비해 검색 성능이 상대적으로 낮기 때문에 관계형 데이터베이스에서도 Elasticsearch를 사용하는 경우가 꽤 있다!
RDB + Elasticsearch 함께 사용하는 경우
- 🔎 검색 엔진 구축
- RDB에서도 LIKE 검색은 여전히 느리지만, Elasticsearch는 역색인을 사용해 매우 빠름
- 예) 쇼핑몰 검색, 블로그 검색, 뉴스 기사 검색
- 📊 로그 분석 및 실시간 데이터 모니터링
- RDB는 실시간으로 수십~수백만 개의 데이터를 처리하는 데 한계가 있음
- Elasticsearch는 실시간 로그 분석이 가능하기 때문에 서버 모니터링, 금융 거래 감시에 적합
- ELK 스택 (Elasticsearch + Logstash + Kibana)을 활용한 실시간 로그 분석
- 🗣️ 데이터 분석 & 자연어 처리 (NLP) 적용
- RDB는 데이터 저장과 트랜잭션 처리에는 강하지만, 데이터 분석과 검색이 느림
- Elasticsearch는 토큰화, 유사어 검색, Fuzzy 검색 등의 기능을 제공하여 NLP 적용이 가능하다
- 예) 챗봇, 고객 리뷰 분석, SNS 데이터 분석
💬 Elasticsearch 말고도 검색 성능을 높일 수 있는 방법
- 적절한 인덱스 설정
- 적절한 인덱스를 활용하면 검색 속도가 최대 수백 배 빨라질 수 있음
- 하지만 인덱스가 많아지면 쓰기 성능이 저하될 수 있음 -> 너무 많은 인덱스는 피해야 함
- NoSQL 기본 인덱스는 고급 검색 기능 (유사어 검색, 퍼지 검색)을 지원하지 않음
- Full-Text Search (FTS) 기능 활용 (유사 검색 기능)
- NoSQL 자체적으로 Full-Text Search 기능을 지원하는 경우가 있음 -> 이 기능을 활용하면 부분 검색, 유사 검색이 가능함
- 하지만 MongoDB의 FTS는 Elasticsearch처럼 강력한 분석 (Analyzer, Tokenizer) 기능이 부족함
- Cassandra, DynamoDB와 같은 일부 NoSQL은 기본적으로 FTS를 제공하지 않음
db.articles.createIndex({ content: "text" }) db.articles.find({ $text: { $search: "Elasticsearch" } })
- 캐싱(Cache) 활용
- 가장 빠른 방법
- 검색 성능을 극대화하려면 Redis, Memcached 같은 캐시 시스템을 활용할 수 있음
- 자주 검색하는 데이터를 Redis에 저장해두고 빠르게 조회하는 방식
- 속도가 빠름 (밀리초 단위 응답) -> Elasticsearch보다 훨씬 빠를 수 있음
- DB에 직접 접근하지 않아 성능 개선됨
- 하지만 실시간 업데이트가 필요한 데이터에는 부적합, 메모리 비용 증가 등의 문제가 있음
- 외부 검색 엔진 사용 (Lucene, Sphinx, Solr)
- Lucene, Solr, Sphinx와 같은 외부 검색 엔진을 사용할 수 있음
- 하지만 Lucene은 직접 구현해야 해서 개발 부담이 큼. Solr은 Elasticsearch보다 설정이 복잡하고 확장성이 떨어질 수 있음
➿ ➿ ➿
📌 Elasticsearch 간단 실습: 인덱스 생성 ~ 검색까지!
1. Elasticsearch 설치 및 기본 설정
Elasticsearch는 자바 기반으로 되어 있어, 설치 전에 JDK(Java Development Kit)가 설치되어 있어야 한다. JDK는 최선 버전을 사용하도록 권장하고 있다. Elasticsearch 설치 공식문서
Elasticsearch의 설정은 elasticsearch.yml 파일에 지정하고 클러스터 이름, 노드 이름, 메모리 등을 설정할 수 있다. 기본 네트워크 설정은 localhost:9200이다!
Elasticsearch를 설치하고 실행하려면 공식 사이트에서 다운로드하거나 Docker를 사용할 수 있다. 다음은 Elasticsearch를 실행할 수 있는 명령어다.
- 로컬에 Elasticsearch를 설치했을 경우
# Elasticsearch 설치 폴더에서 elasticsearch.bat 실행 또는 다음의 명령어 실행 bin/elasticsearch.bat - 도커를 사용한 Elasticsearch 실행
# Docker를 이용한 Elasticsearch 실행 docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.10.0
2. 인덱스 생성 예제
curl -X PUT "http://localhost:9200/my_index" -H "Content-Type: application/json" -d '{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"title": { "type": "text" },
"views": { "type": "integer" },
"published_at": { "type": "date" }
}
}
}'
3. 문서 추가 및 검색 예제
# 문서 추가
curl -X POST "http://localhost:9200/my_index/_doc/1" -H "Content-Type: application/json" -d '{
"title": "Elasticsearch 인덱스 개념",
"views": 150,
"published_at": "2024-02-13"
}'
# 문서 검색
curl -X GET "http://localhost:9200/my_index/_search" -H "Content-Type: application/json" -d '{
"query": {
"match": {
"title": "Elasticsearch"
}
}
}'
참고
Related Posts
| 개발 | AI를 빠르고 쉽게 서빙하는 방법, BentoML | |
| 구글코리아 x Project | LLM 기반 사내 데이터 분석 엔진, DBDeep | |
| NLP | 벡터 유사도 (Vector Similarity) 파헤치기 |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).