개발 | AI를 빠르고 쉽게 서빙하는 방법, BentoML
요새 산업을 가리지 않고 AI 기술이 다양한 영역에서 사용되고 있다. 인공지능을 처음 배울 당시만 해도 데이터 처리, 그리고 모델의 구조나 성능에만 집중했다. 어떤 구조를 가져가는 것이 모델이 기존의 feature를 잃지 않으면서 성능을 더 높일 수 있을까? 어떻게 해야 과적합을 줄일 수 있을까? 이런 고민들을 했었던 기억이 난다.
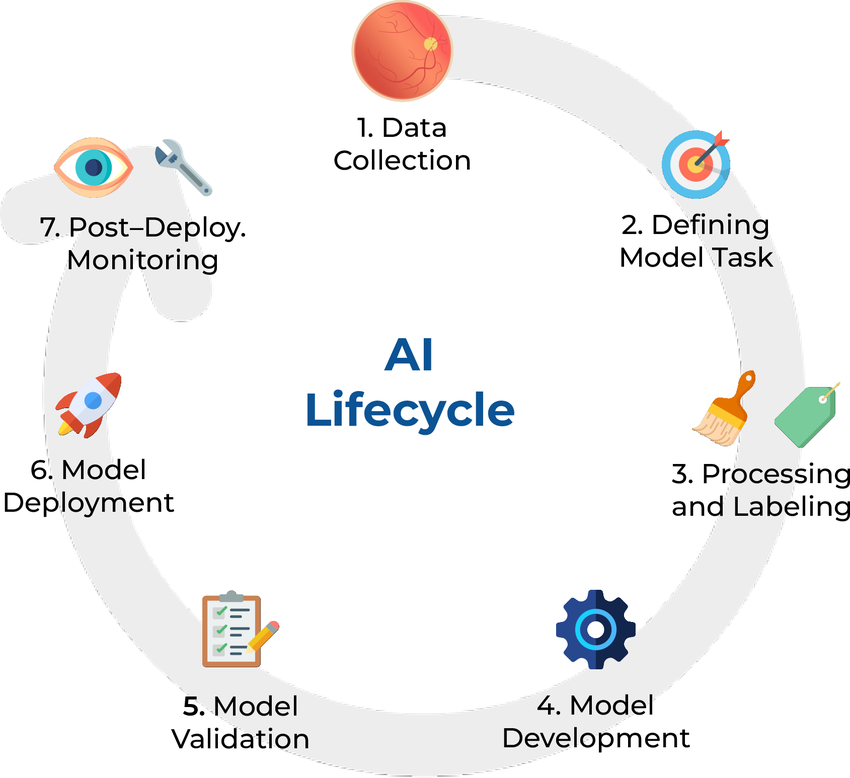
위 그림처럼 AI 개발의 단계를 나눈다면, 그동안은 1-5까지의 단계만 신경썼던 셈이다.
막상 싸피(SSAFY)에서 기획부터 배포까지의 프로젝트를 직접 진행하면서, 학습시킨 모델을 API 형태로, 실제 서비스로 배포하는 과정에 있어서 고려해야할 게 훨씬 많다는 것을 체감했다. 모델의 성능을 최대한으로 끌어올렸지만 실제 서비스 환경에서 이 성능으로, 필요할 때, 모델을 서빙할 수 없다면 문제가 발생한다. 백엔드 개발자에게 ‘모델 만들었으니까 API 만들어줘’라고 단순히 일임하기엔 모델의 파이프라인을 설계하고 학습시킨 AI 개발자의 시선이 필요했기에 결국에 내가 API 코드까지 작성하게 되었다.
사용자가 실시간으로 요청을 보낼 수 있는 형태로 API를 만들고, 서버 환경에 맞게 전처리 과정도 동일하게 진행될 수 있도록 해야했으며, 트래픽이 몰릴 때도 안정적으로 응답하도록 백엔드 개발자와 이야기를 나누며 설계해야 했다.
이런 과정들을 신경 쓰지 않고도, AI 모델 학습에만 집중할 수 있다면 얼마나 좋을까?
AI 모델 학습에만 집중하고, 배포나 관리 과정은 시스템이 대신 처리해 준다면 훨씬 효율적일 것이다. 그래서 이미 많은 기업들은 이미 이런 구조를 가능하게 하는 AI 플랫폼을 구축하고 있다. IT 회사는 물론이고, 최근에는 AI에 대해 비교적 보수적인 입장을 취할 수 밖에 없었던 시중은행도 ‘AI Transformation(AX)’의 일환으로 AI 플랫폼 도입을 서두르고 있다.
AI 플랫폼
AI 기술을 실제 비즈니스에 접목시키기 위해서는 생각보다 많은 요소가 필요하다. 데이터를 어떻게 수집하고 관리할지, 모델을 어떻게 학습·검증할지, 그리고 학습된 모델을 어떻게 서비스 환경에서 불러오는 과정 등 여러 컴포넌트가 복잡하게 얽혀 있다.
이러한 컴포넌트를 유기적으로 결합하여 쉽게 가져다 쓸 수 있게 만든 시스템이 바로 AI 플랫폼이다. 데이터 파이프라인, 모델 학습, 서빙, 모니터링 등 AI 개발과 운영의 전 과정을 통합해 개발자가 더 빠르고 안정적으로 AI 서비스를 제공할 수 있도록 돕는다.
🫵 배움에는 끝이 없다고 한다. AI 너도?
나는 AI Lab에서 인턴으로 근무하며 이 사실을 체감했다. 이전에 학부과정에서 했던 프로젝트들은 단기성으로, 프로젝트를 완성한 시점이 곧 끝이었다. 그런데 실제 현업에서는 이야기가 다르다. 데이터는 계속해서 생성되고, 이 데이터를 기반으로 모델은 끊임없이 재학습되어야 한다. 지금 생각하면 너무 당연한 일인데, 그 전까지는 모델의 ‘지속성’을 한 번도 깊게 고민해 본 적이 없었다.
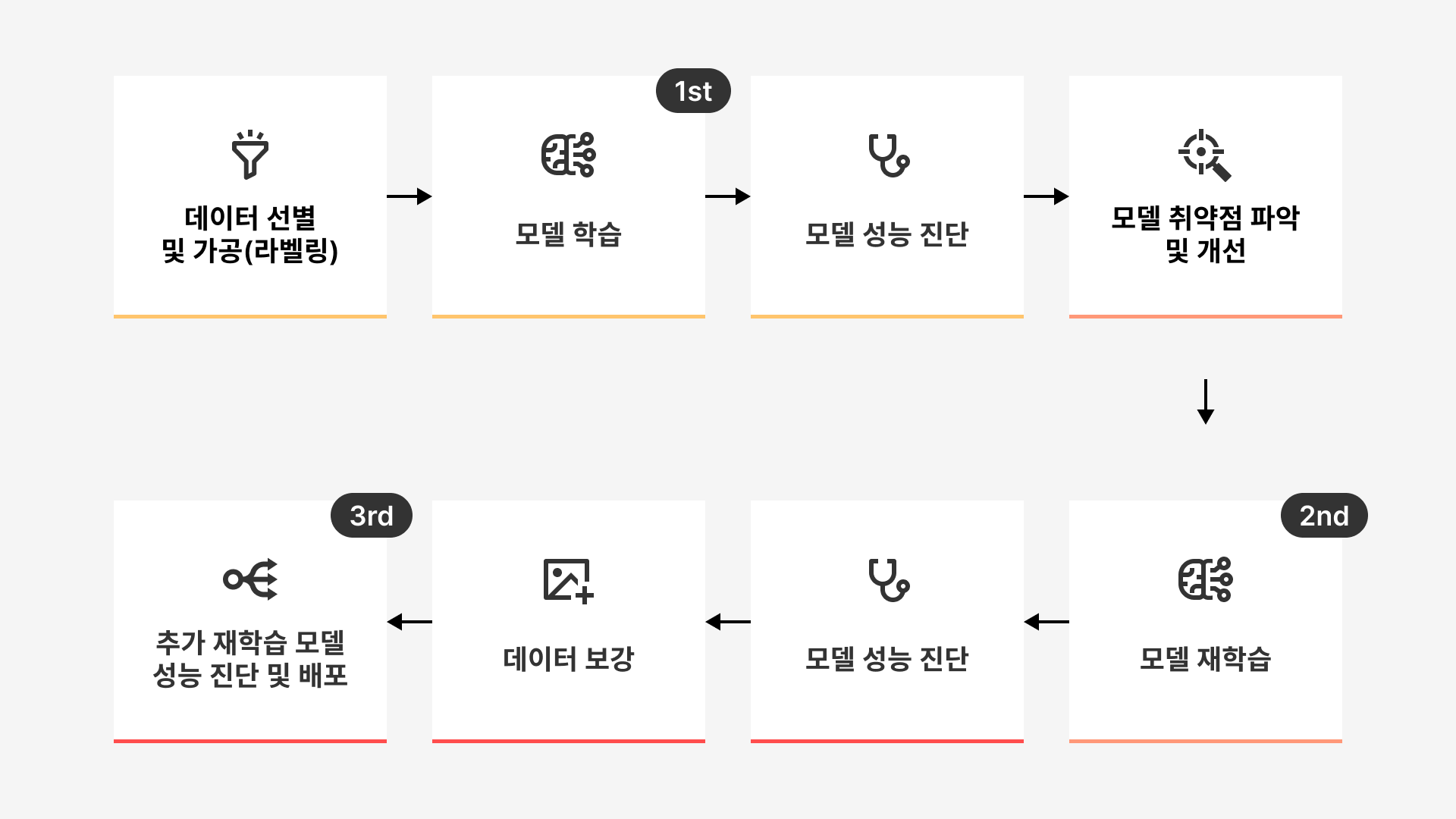
❓ 서빙이란
서빙은 학습된 AI 모델을 실제 서비스(운영) 환경에 배포하여 사용자가 실시간으로 요청할 수 있도록 API 형태로 제공하는 과정을 말한다.
매일 엄청난 양의 데이터가 생성되고 이 데이터를 이용해 AI 모델이 꾸준히 학습하게 되기에, AI 모델을 안정적으로 빠르게 서빙하는 것이 무엇보다 중요하다. 현재 AI플랫폼의 서빙 시스템은 약 20억/월 건의 트래픽을 처리하고 있다고 한다. 이를 위해 모델 버전 관리, 다시 배포하는 과정에 유실이 없도록 하는 무중단 배포, 문제가 있을 때 빠르게 복구하기 위한 롤백 처리 등이 철저히 이루어진다. < 출처: 우아한기술블로그
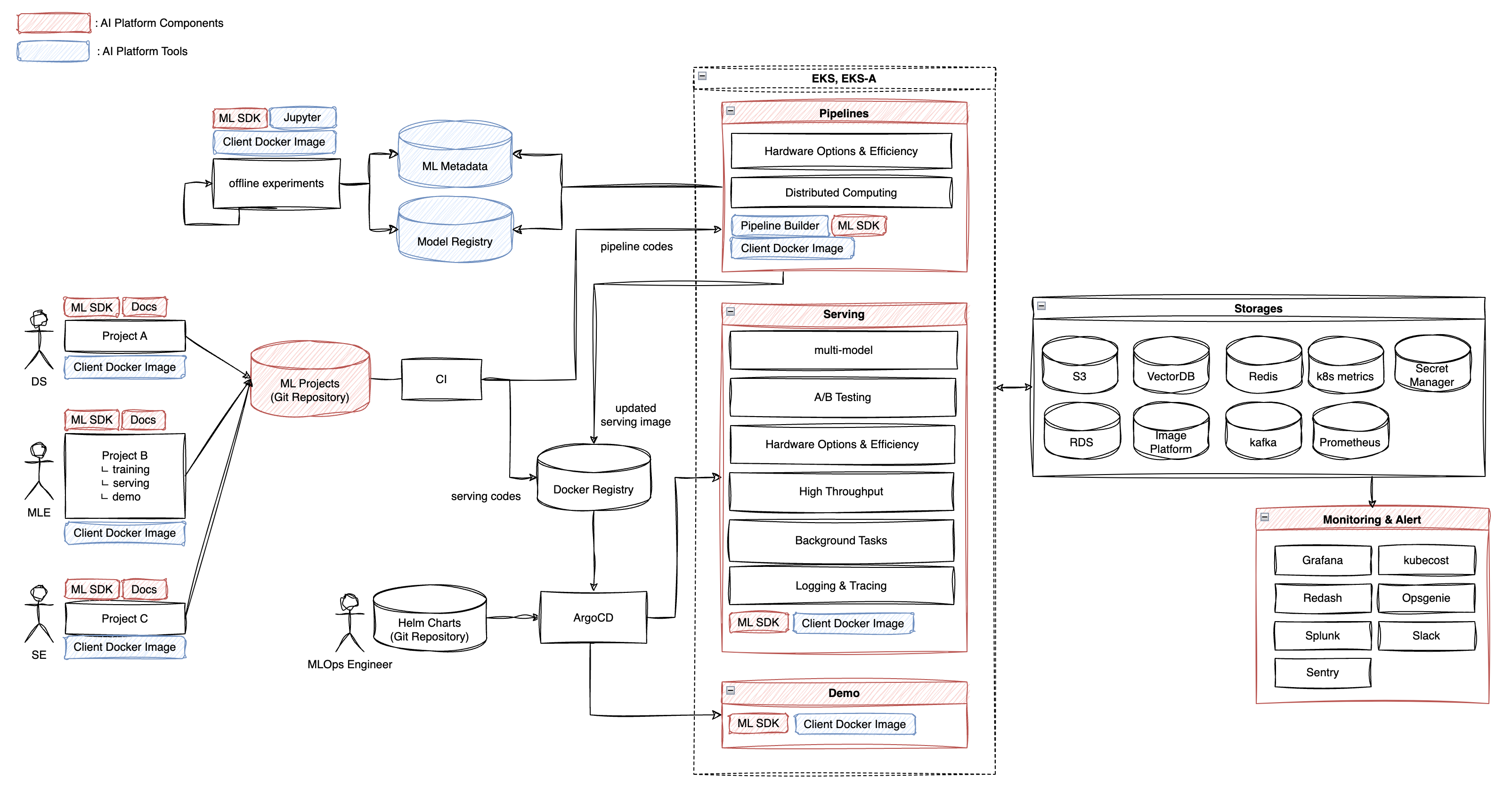
AI 모델을 도시락처럼 포장하고 배달하기, BentoML
AI 개발자는 PyTorch, TensorFlow, Scikit Learn 등 다양한 프레임워크와 라이브러리를 사용해 모델을 학습시킨다. 다양한 모델을 서빙하다 보면 다양한 프레임워크와 라이브러리를 가지는 모델 모두를 서빙할 수 있어야 하는데, 서로 모델을 불러오고 추론하는 방식이 달라 코드 일관성 유지와 유지 보수가 어려워지고 시스템 복잡성이 증가하는 문제가 생긴다.
모델러의 입장에서 생각해보자. 모델러는 더 좋은 서비스를 제공하기 위해 자신이 만든 모델을 빠르게 배포하고 더 많은 피드백을 받아서 개선하고자 한다. 이전에는 모델 서빙 과정이 서버 엔지니어링 과정과 결합되어 있어서 배포가 까다로웠고 배경지식을 많이 필요로 했다.
Model Serving에 특화된 라이브러리 BentoML
이 문제를 해결해 주는 도구가 바로 BentoML이다. Bento는 일본어로 도시락이라는 뜻으로, 모델 Artifact 및 코드를 도시락처럼 포장(Packing)하고 배달(Deploy, 배포)까지 자동으로 해준다고 생각하면 될 것 같다.

BentoML은 여러 프레임워크를 지원하며, 모델을 손쉽게 컨테이너화(Containerization) 할 수 있게 도와준다. 이후 Kubernetes 배포도 간편해지고, 전·후처리 로직을 쉽게 추가할 수 있어 개발 속도를 높일 수 있다.
BentoML의 또다른 장점 중 하나는 여러 ML 프레임워크와 연동할 수 있다는 것이다. AI 모델링에 사용되는 Scikit-Learn, PyTorch, Tensorflow, Keras, FastAI, XGBoost, LightGBM, CoreML 등 주요 프레임워크와 연동해 모델을 서빙할 수 있다.
특히, 기업에서는 이러한 장점과 더불어 사내 ML 플랫폼에서 쉽게 BentoML 환경을 구성할 수 있어 많이 채택하고 있다고 알고 있다. ex) 우아한형제들, 라인
BentoML의 기본 구조와 코드
BentoService 개념
bentoml.BentoService는 예측 Service를 만들기 위한 기본 클래스다. @bentoml.artifacts 데코레이터를 통해 여러 머신러닝 모델을 포함할 수 있다. BentoService는 save() 메소드를 통해 머신러닝 프레임워크, Arifact를 기반으로 모델을 저장한다. BentoService 클래스에 필요한 dependency들을 자동으로 추출하여 requirements.txt에 저장한다.
API Function & Adapters
BentoService API는 클라이언트가 예측 서비스에 접근하기 위한 End-Point이다. Adapters는 API callback 함수를 정의하고 다양한 형태로 예측을 요청하는 추상화 레이어라고 생각하면 된다.
다음 예시는 BentoML에서 단일 모델을 간단히 API 형태로 서빙하는 방법이다.
class ExamplePredictionService(bentoml.BentoService):
@bentoml.api(input=DataframeInput(), batch=True)
def predict(self, df):
assert type(df) == pandas.core.frame.DataFrame
return postprocessing(model_output)
아래처럼 모델 예측 전후처리를 추가로 수행하도록 작성할 수 있다.
from my_lib import preprocessing, postprocessing, fetch_user_profile_from_database
class ExamplePredictionService(bentoml.BentoService):
@bentoml.api(input=DataframeInput(), batch=True)
def predict(self, df):
user_profile_column = fetch_user_profile_from_database(df['user_id'])
df['user_profile'] = user_profile_column
model_input = preprocessing(df)
model_output = self.artifacts.model.predict(model_input)
return postprocessing(model_output)
이처럼 간단히 작성해두면, /predict 경로로 API 호출 요청을 보낼 때 모델 추론 결과를 얻을 수 있다. 나머지 모든 작업은 AI 플랫폼에서 자동으로 해준다.
Model Artifact 패키징
Artifact API (@artifacts)를 사용하면 모델을 지정해서 불러올 수 있다. 해당 API를 통해 모델을 Load하면 모델 Serialization, Deserialization을 자동으로 처리해준다. @bentoml.artifacts([ ])를 이용해서 여러 Artifact를 지정할 수도 있다.
import bentoml
from bentoml.adapters import DataframeInput
from bentoml.frameworks.sklearn import SklearnModelArtifact
from bentoml.frameworks.xgboost import XgboostModelArtifact
@bentoml.env(infer_pip_packages=True)
@bentoml.artifacts([
SklearnModelArtifact("model_a"),
XgboostModelArtifact("model_b")
])
class MyPredictionService(bentoml.BentoService):
@bentoml.api(input=DataframeInput(), batch=True)
def predict(self, df):
# assume the output of model_a will be the input of model_b in this example:
df = self.artifacts.model_a.predict(df)
return self.artifacts.model_b.predict(df)
svc = MyPredictionService()
svc.pack('model_a', my_sklearn_model_object)
svc.pack('model_b', my_xgboost_model_object)
svc.save()
BentoML 모델 관리와 배포
Model Artifact Metadata
AI 모델은 학습이 끝난 시점이 아니라, 서빙 후에도 지속적으로 관리되어야 한다. 그래서 모델 자체뿐 아니라 모델에 대한 부가 정보(메타데이터)를 함께 저장하는 것이 중요하다. 메타데이터에는 모델의 성능 지표(Accuracy, Precision, Recall 등), 학습 데이터셋 버전, 생성 일자, 작성자, 사용 환경 등의 정보를 담을 수 있다.
BentoML에서는 모델을 pack()할 때 metadata 인자를 통해 이러한 정보를 쉽게 기록할 수 있다. 이렇게 저장된 메타데이터는 이후 버전 관리나 모델 비교, 모니터링 과정에서 중요한 기준으로 활용될 수 있다.
아래 코드는 두 개의 모델(model_a, model_b)을 각각 메타데이터와 함께 패키징하는 예시 코드다.
svc = MyPredictionService()
svc.pack(
'model_a',
my_sklearn_model_object,
metadata={
'precision_score': 0.876,
'created_by': 'joe'
}
)
svc.pack(
'model_b',
my_xgboost_model_object,
metadata={
'precision_score': 0.792,
'mean_absolute_error': 0.88
}
)
svc.save()
Model Artifact Metadata를 보는 코드는 다음과 같다.
from bentoml import load
svc = load('path_to_bento_service')
print(svc.artifacts['model'].metadata)
BentoML의 Deploy 배포
BentoML을 통해 간단하게 API를 띄울 수 있게 되었다. AI 개발자는 다른 개발 과정을 신경 쓸 필요 없이 모델링에만 집중할 수 있게 된 것이다. 이제 그 서비스를 사용자가 이용하게 하려면 배포라는 과정이 필요하다.
BentoML은 AI 개발자가 만든 모델을 호출하는 API를 쉽게 하도록 할 뿐만 아니라, 실제 실행 환경에 배포하기 위한 단계까지 함께 제공한다. 간단하게 방법을 소개하자면 다음과 같다.
Deploy
프로젝트 루트 디렉토리에서 BentoCloud에 deploy하기 위해선 다음의 코드를 실행하면 된다. 배포 단위의 이름은 원하는 대로 지어주면 된다. 아래 코드를 예시로 들자면 my-first-bento로 지은 셈이다.
bentoml deploy --name my-first-bento
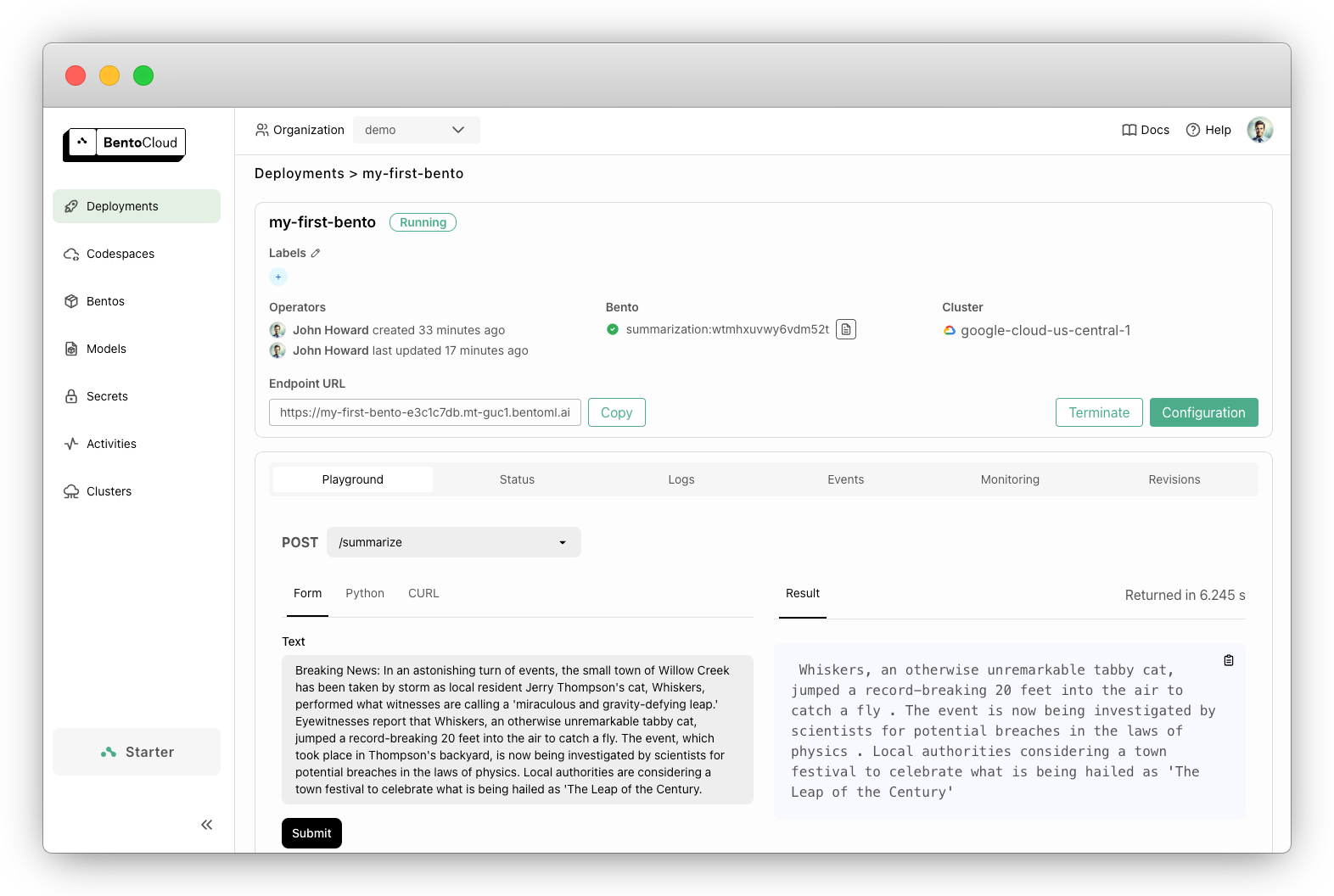
성공적으로 deploy가 됐다면, 아래 그림처럼 BentoCloud 콘솔에서 Deployments로 들어갔을 떄 my-first-bento를 확인할 수 있다.
Call the Deployment endpoint
여기까지 됐다면 이제 위에서 우리가 만들었던 API를 불러올 수가 있다! 배포가 되어있는 API 엔드포인트를 확인해보자. endpoint URL는 BentoCloud에서 확인할 수 있다. (바로 위 그림 참고)
만약 수정하고 싶다면 터미널에 아래 코드를 실행해 수정할 수 있으며, 코드 내에서 내부 파라미터를 사용해 엔드포인트 URL을 커스텀할 수도 있다.
bentoml deployment get my-first-bento -o json | jq ."endpoint_urls"
# 내부 파라미터 route를 이용해 커스텀하는 예시 코드
@env(infer_pip_packages=True)
@artifacts([
...
])
class ModelApiService(BentoService):
@api(input=ModelApiInputValidator(),
output=JsonOutput(),
route="v1/service_name/predict",
mb_max_latency=200,
mb_max_batch_size=500,
batch=False
)
def predict_v1(self, df: pd.DataFrame):
...
return result
자, 실전이다. 드디어 API 호출해볼게요! 호출하기 위해서는 BentoML Client를 생성해주어야 하는데 아래의 코드를 통해 생성할 수 있다.
import bentoml
client = bentoml.SyncHTTPClient("https://my-first-bento-e3c1c7db.mt-guc1.bentoml.ai")
result: str = client.summarize(
text="Breaking News: In an astonishing turn of events, the small town of Willow Creek has been taken by storm as local resident Jerry Thompson's cat, Whiskers, performed what witnesses are calling a 'miraculous and gravity-defying leap.' Eyewitnesses report that Whiskers, an otherwise unremarkable tabby cat, jumped a record-breaking 20 feet into the air to catch a fly. The event, which took place in Thompson's backyard, is now being investigated by scientists for potential breaches in the laws of physics. Local authorities are considering a town festival to celebrate what is being hailed as 'The Leap of the Century.",
)
print(result)
🎉 축하합니다 🎉
여기까지 하면 배포도 성공! 엔드포엔트 호출도 성공! 🚀 이렇게 내가 만든 AI 모델을 쉽게 호출해 사용할 수 있게 되었다!
Deployment update
코드를 수정하면 배포를 다시 해야 서비스에 반영이 된다. 다시 배포하는 코드는 다음과 같다.
bentoml deployment update my-first-bento --bento ./project/directory
배포를 하다보면 트래픽에 따라 크기 scaling이 필요한 경우도 있다. 필요하다면 scaling이나 terminate에 관한 내용은 공식 문서를 참고하기 바란다.
배포 자동화 - CI/CD
그치만 코드를 조금씩 바꿀 때마다 배포를 다시 해주어야 하는 것은 조금 수고스럽다. 그래서 일반적으로 지속적인 개발 환경에서는 변경 사항을 안정적으로, 바로바로 반영하기 위해 CI/CD를 함께 운영한다.
✅ CI (Continuous Integration)
CI 단계에서는 개발자가 코드를 커밋할 때마다 품질 검증과 패키징이 자동으로 수행된다.
인프라는 잘 모르지만 전에 싸피에서 구글 연계 프로젝트를 진행할 때, 인프라 담당 팀원이 배포 자동화를 Jenkins 파이프라인으로 구성해 주었다. 내가 이해한 내용을 간략하게 설명하자면 다음과 같다.
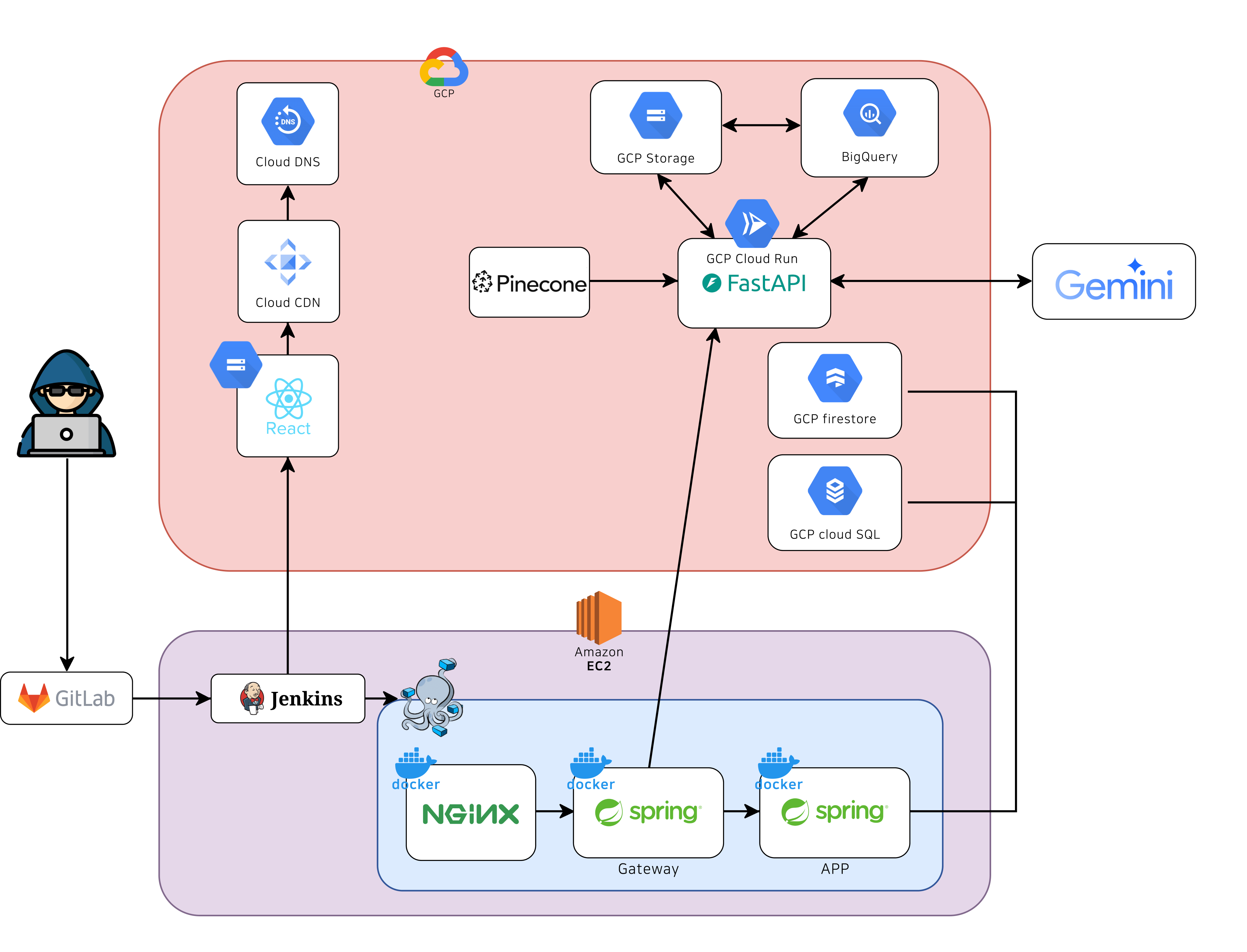
내가 만든 서비스 코드를 GitLab에 푸시하면, Jenkins가 이를 감지해 다음 단계를 수행한다.
- 코드 빌드 및 테스트 실행
- 프론트/백/AI 각각 빌드 테스트를 거침
- 빌드 테스트는 코드 통합 시 충돌(컴파일 에러, 의존성 충돌 등)을 방지하기 위해 필요한 단계로 빌드 테스트를 통과하지 않은 코드를 배포하면 서비스가 바로 먹통이 될 수 있음
- Docker 이미지 생성
- 빌드가 통과되면 Docker 이미지를 자동으로 생성하고 Registry에 푸시
- Docker 이미지는 코드 + 실행환경(OS, 라이브러리, 의존성)을 한 덩어리로 묶어 어디서 실행하든 동일한 환경에서 돌게 지원
- Cloud Run 또는 AWS EC2로 Docker 이미지 전달 준비
이렇게 CI 단계에서 생성된 이미지를 이용해 이후 CD 단계에서 실제 서비스로 배포한다.
✅ CD (Continuous Deployment)
CD 단계에서는 생성된 이미지를 실제 서버에 자동 반영한다.
특히 AI 부분 코드는 Google Cloud Platform(GCP)의 Cloud Run을 통해 동적 배포되었다. Cloud Run은 컨테이너 이미지를 기반으로 서버를 자동으로 실행하는 서버리스 환경이다. 덕분에 서버 인프라(가상머신, 로드 밸런서, 스케일링 등)를 직접 관리할 필요가 없었다.
내가 만든 서비스 코드를 GitLab에 푸시하면 젠킨스에서 빌드 테스트를 거쳐 Docker 이미지가 생성된다. 이렇게 만들어진 컨테이너 이미지를 Cloud Run에서 빌드하고 배포가 완성된다. 즉, GitLab → Jenkins → Docker → Cloud Run까지 파이프라인이 완성되어 코드 수정 후 푸시만 해도 자동으로 새 버전이 배포되는 구조였다.
❓ 배포 정책 설계에 대한 고민
다만, 모든 상황에서 이렇게 무중단으로 자동 배포하는 정책이 좋은 건 아니고 상황별로 접근하는 것이 좋다.
단순 로직만 변경되는 경우나, 재학습 파이프라인에 의해서 모델이 특정 주기를 가지고 새로 학습되는 경우엔 기존의 큰 틀과 거의 달라진 게 없으므로 큰 문제가 없다. 이런 경우는 서비스를 중단하지 않고 점진적으로 업데이트하는 방식, 무중단 자동 배포를 진행해도 된다.
그러나 API 입출력이 변경되는 경우와 같이 큰 틀이 바뀌면 기존 API 와 연동되지 않을 것이다. 그래서 CI 파이프라인에 API 명세 변경 사항을 비교하는 단계를 추가해 현재 서빙되는 API와 새로 생성되는 API 사이에 호환되지 않는 경우가 있는지 감지할 수 있게 한 후, 새 버전이 생성되고 API 호출을 모두 새로운 버전으로 전환하고 기존 버전을 삭제하는 형태로 수동 배포를 진행하는 식으로 진행하면 될 것 같다.
Model Serving
Bento로 패키징한 서비스는 Online / Batch / Edge 세 가지 방식으로 배포할 수 있다. 방식별로 요구사항이 다르기 때문에, 먼저 요청 패턴·지연 허용 범위·리소스 제약을 기준으로 선택하는 게 깔끔하다.
1️⃣ Online Serving (실시간 API)
- 사용자 요청-응답이 1:1로 맞물릴 때. 검색, 추천, 챗봇, 결제 리스크 판단 등.
2️⃣ Offline Batch Serving (일괄 추론)
- 하루 1회 이상 주기성 작업, 대량 스코어링/리랭킹/정산.
3️⃣ Edge Serving (온디바이스/엣지)
-
언제? 네트워크가 불안정하거나 개인정보가 로컬을 못 벗어나는 환경.
이외 클라우드 환경
BentoService로 패키징된 모델은 로컬 환경뿐 아니라 클라우드 환경에서도 쉽게 배포할 수 있다. GCP AI Platform(현 Vertex AI), AWS SageMaker, Azure ML 등 주요 클라우드 환경에서 BentoML을 바로 연동해 서빙할 수 있으며, 공식 문서에서 구체적인 배포 방법이 정리되어 있다. < GCP 배포 가이드 보기
정리
💬 AI 또한 서비스되어야 사용자가 이용할 수 있다
BentoML은 많이 알려진 머신러닝 모델 배포 관리 도구 중 하나이다. 모델을 프레임워크에 구애받지 않고 포장(pack)하고, 손쉽게 배포(deploy)하며, API 형태로 빠르게 서빙할 수 있도록 해준다. 덕분에 AI 개발자는 인프라 걱정보다 문제 해결과 모델 개선에 더 집중할 수 있다.
내가 BentoML을 중심적으로 정리한 이유는, “AI 모델을 어떻게 실제 서비스로 연결할 것인가?”라는 질문에 가장 직관적인 해답을 주는 도구이기 때문이다. 싸피(SSAFY)에서 직접 모델을 FastAPI 형태로 배포하면서, 복잡한 인프라 구성과 의존성 문제로 많은 시행착오를 겪었다. 그때 모델을 쉽게 패키징하고 바로 API로 띄울 수 있었다면 개발 효율이 훨씬 높았을 것이라는 생각이 들었다. BentoML은 바로 그 부분을 자동화하고, AI 개발자에게 필요한 최소한의 배포 자유도를 보장해 준다.
물론, BentoML만이 유일한 해답은 아니다. KServe, TorchServe, TensorFlow Serving 같은 다양한 서빙 프레임워크가 존재하며, 각각의 환경(클라우드, 온프레미스, 엣지)에 맞게 선택하는 것이 중요하다. 하지만 AI 플랫폼을 처음 설계하거나 빠르게 프로토타입을 만들어야 하는 상황이라면, BentoML은 가장 직관적이고 효율적인 선택이 될 수 있다.
참고
- 우아한기술블로그 > 제목은 안정적인 AI 서빙 시스템으로 하겠습니다. 근데 이제 자동화를 곁들인…
- Machine Learning Serving - BentoML 사용법
- BentoML Github
- Line Engineering > MLOps를 위한 BentoML 기능 및 성능 테스트 결과 공유 - 1
Related Posts
| 구글코리아 x Project | LLM 기반 사내 데이터 분석 엔진, DBDeep | |
| NLP | 벡터 유사도 (Vector Similarity) 파헤치기 | |
| GCP | BigQuery 활용하기 (성능 최적화, 인덱스, SQL문 검증 및 실행까지!) |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).