크롤링 / 웹 스크래핑 - 네이버 뉴스 기사 댓글 수집하기
주의할 점을 잘 숙지하고 원하는 대로 네이버 뉴스 댓글을 크롤링해보자.
[📌 주의할 점]
- 네이버 뉴스 기사 댓글 -> header에 “referer”을 추가해주어야 접근할 수 있다.
- 네이버 뉴스 기사 댓글은
더보기버튼을 눌러야 더 많은 댓글을 확인할 수 있다. ''으로 수집된 댓글은삭제된 댓글이다.
다음 링크를 참고하였다.
네이버 뉴스 기사 댓글 가져오기
멋사 AI에서 미니프로젝트1을 진행하면서 기억하면 좋을 점을 기록해놓으려고 한다. 아래의 방법은 ‘더보기’를 누를 정도로 많은 뉴스 기사 1개에 대한 댓글을 수집하는 방법이다. 셀레니움을 쓰면 오래 걸리는 작업을 request로 쉽게 받아올 수 있다.
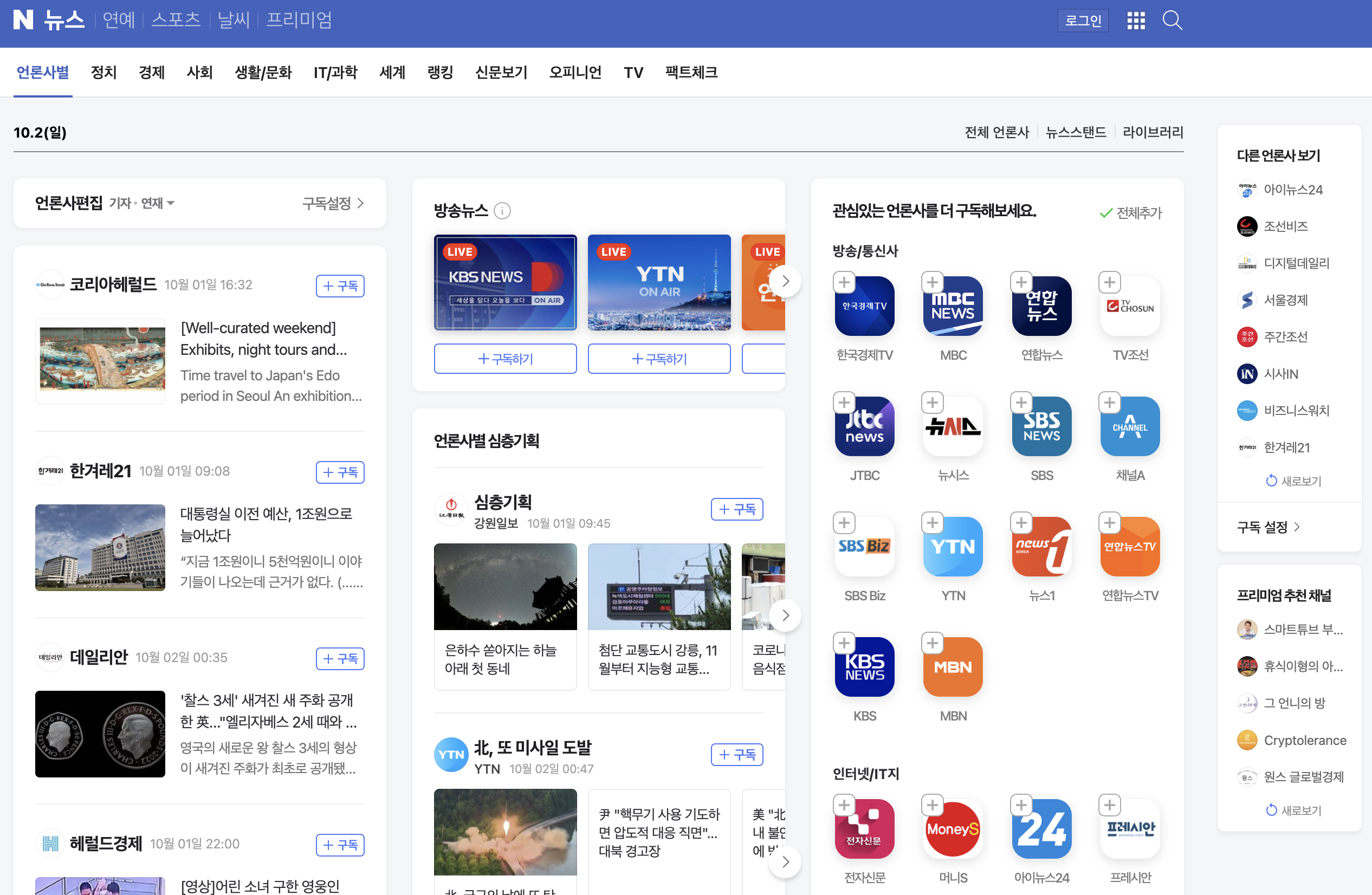
1. URL 가져오기
뉴스 기사 댓글 부분으로 들어가면 해당 기사에 대한 댓글만 볼 수 있다. 이 페이지에서 마우스 우클릭 > 검사 (Inspect) > Network를 눌러 다음과 같은 창이 나오면 🚫 표시를 눌러 초기화해준다.
다시 뉴스 댓글 부분으로 돌아오자.
여기서 밑으로 스크롤을 내리면 보이는 더보기 버튼을 눌러주면 JS request가 새로 생긴 것을 볼 수 있다.
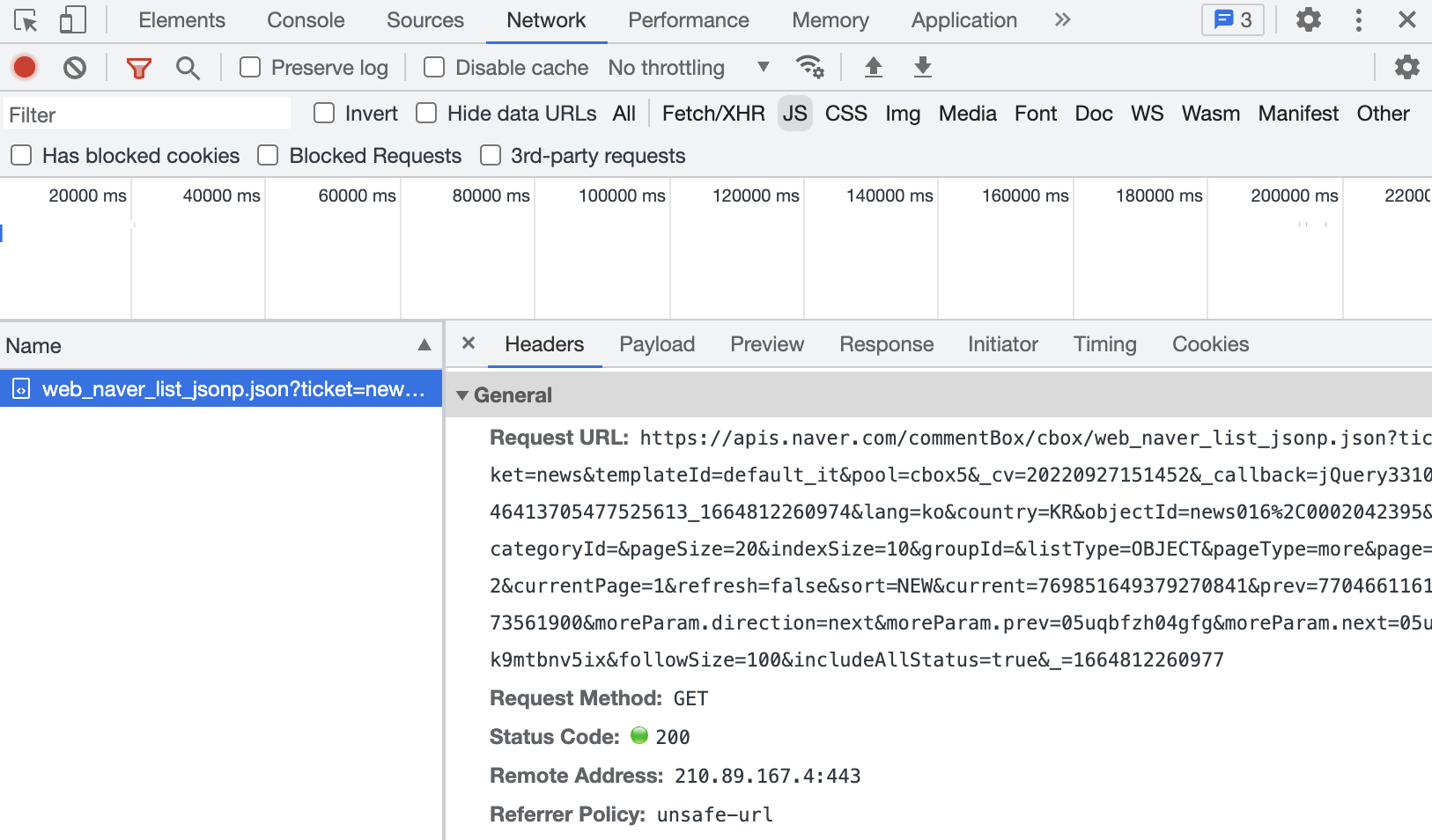
url은 이 부분의 Headers에 있는 Request URL을 참고해서 가져올 것이다.
user-agent 는 크롬에서 chrome://version/를 입력하면 확인할 수 있다!
news_url = "https://apis.naver.com/commentBox/cbox/web_naver_list_jsonp.json?ticket=news&templateId=default_it&pool=cbox5&_cv=20220927151452&_callback=jQuery331019634359292220194_1664536607172&lang=ko&country=KR&objectId=news016%2C0002042395&categoryId=&pageSize=20&indexSize=10&groupId=&listType=OBJECT&pageType=more&page=2¤tPage=1&refresh=false&sort=NEW¤t=769851649379270841&prev=770466116173561900&moreParam.direction=next&moreParam.prev=05uqbfzh04gfg&moreParam.next=05uk9mtbnv5ix&followSize=100&includeAllStatus=true&_=1664536607175"
header = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
html = requests.get(url, headers = header)
soup = bs(html.content, 'html.parser')
soup
위와 같은 코드를 실행하면 다음과 같은 json 형태의 결과값을 확인할 수 있다.
jQuery331019634359292220194_1664536607172({"success":false,"code":"3999","message":"잘못된 접근입니다.","lang":"ko","country":"KR","result":{},"date":"2022-09-30T11:22:13+0000"});
⚠️ 잘못된 접근?
이미 로봇이 아님을 증명하는 user-agent를 추가해줬는데 무엇이 문제일까?
구글링 결과, 다음 링크에서 답을 찾았다.
잘못된 접근이라고 뜬다면 이는 이전 페이지에 대한 참조가 없기 때문이다. 네이버 뉴스의 댓글은 더보기 버튼을 눌러서 댓글을 더 볼 수 있는 형태이기 때문에 이전 페이지를 참조한다. 이를 나탄태는 ‘referer’ 값을 추가해줘야 한다는 것이다.
header = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"referer" : "https://n.news.naver.com/article/comment/016/0002042395"}
html = requests.get(url, headers = header)
soup = bs(html.content, 'html.parser')
soup
‘referer’을 추가하여 실행해보면 다음과 같이 “요청을 성공적으로 처리하였습니다.“와 같은 메시지가 뜨면서 댓글을 받아오는 것을 확인할 수 있다.

후처리
jQuery331019634359292220194_1664536607172로 감싸져 있는 부분만 추출해오기 위해 _callback 부분을 url에서 빼준다. 이렇게 한 뒤 위의 코드를 실행해주면 저 긴 jQuery~ 대신 _callback으로 감싸져 있는 구조로 바뀐다. 이외에 조금의 파라미터 조정을 통해 내가 원하는 데이터를 받아오도록 해보자. url의 파라미터는 다음 코드를 통해 확인할 수 있다.
# url에 붙은 parameter 확인하기
from urllib.parse import urlparse, parse_qs
url_param = parse_qs(urlparse(url).query)
url_param
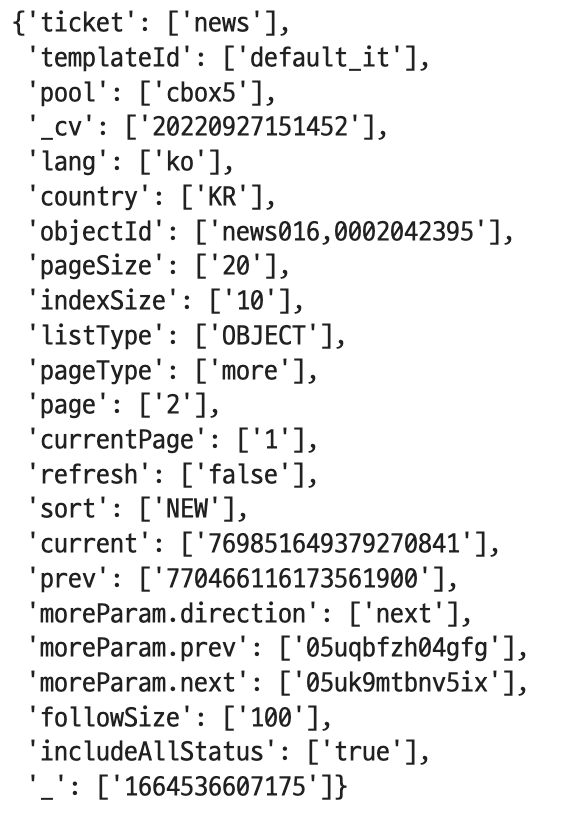
위의 결과를 참고해서 url 주소를 조금 바꿔주었다. 여기서 pageSize는 수집해 올 댓글의 개수를 의미한다. 나는 현재 sort=NEW로, 최신순으로 정렬되어 있지만 공감순으로 바꾸고 싶다면 sort=favorite으로 바꾸면 된다.
news_url = "https://apis.naver.com/commentBox/cbox/web_naver_list_jsonp.json?ticket=news&templateId=default_it&pool=cbox5&_cv=20220927151452&lang=ko&country=KR&objectId=news016,0002042395&pageSize=100&indexSize=10&listType=OBJECT&pageType=more&page=1&refresh=false&sort=NEW¤t=769851649379270841&prev=770466116173561900&moreParam.direction=next&moreParam.prev=05uqbfzh04gfg&moreParam.next=05uk9mtbnv5ix&followSize=100&includeAllStatus=true&_=1664536607175"
header = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7",
"referer" : "https://n.news.naver.com/article/comment/016/0002042395"}
html = requests.get(news_url, headers = header)
이제 원하는 부분만 뽑기 위해 _callback 부분을 제거해서 key - value 접근이 편한 json 값으로 변환해주자.
# json 파일로 변환해주기
news_text = html.text
news_text = news_text.replace("_callback(","")
comment_text = json.loads(news_text[:-2])
2. 댓글만 가져오기
comment_text에서 댓글만 가져오는 코드를 작성해보겠다.

댓글은 comment_text의 ‘contents’에 위치해 있다.
temp_comment_list = [comment_info['contents'] for comment_info in comment_text['result']['commentList']]
comment_all.extend(temp_comment_list)
comment_all
위의 코드를 실행하면 댓글이 list 형태로 잘 담겨 있는 것을 확인할 수 있다.

3. 데이터 전처리
위에서 댓글의 특성상 특수 문자가 포함되어 있으며, 개행문자는 문자 ‘\n’으로 저장되어 있는 것을 확인했다. re 라이브러리를 통해 특수문자를 제거해주고, replace를 이용해 ‘\n’을 제거해주겠다.
re_comment = []
for comment in comment_all:
c = re.sub('[^\w\s]', '', comment)
c = c.replace('\n', ' ')
re_comment.append(c)
이를 데이터프레임 형태로 나타내주었더니 공백으로 출력되는 행이 있었다. 확인해보니, 이는 삭제된 댓글이었다. 이를 모두 “====== 삭제된 댓글입니다. ======“으로 바꿔주었다.
# ''로 출력되는 행 -> '삭제된 댓글입니다'로 변경
df = comment_df_final.copy()
for i in range(len(df)):
if len(df['comment'][i]) == 0:
df['comment'][i] = "====== 삭제된 댓글입니다. ======"

4. 더 많은 댓글 수집하기
자, 응용해서 ‘더보기’를 원하는 횟수만큼 눌러 댓글을 가져와보자!
news_url = "https://apis.naver.com/commentBox/cbox/web_naver_list_jsonp.json?ticket=news&templateId=default_it&pool=cbox5&_cv=20220927151452&lang=ko&country=KR&objectId=news016,0002042395&pageSize=80&indexSize=10&listType=OBJECT&pageType=more&page={}&refresh=false&sort=NEW¤t=769851649379270841&prev=770466116173561900&moreParam.direction=next&moreParam.prev=05uqbfzh04gfg&moreParam.next=05uk9mtbnv5ix&followSize=100&includeAllStatus=true&_=1664536607175"
header = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7",
"referer" : "https://n.news.naver.com/article/comment/016/0002042395"}
format 함수를 이용하면 원하는 값을 url에 넣어줄 수 있다는 점을 이용하자. 수집할 총 댓글 수가 최소 100개가 되도록 코드를 작성하면 아래와 같이 작성할 수 있다.
page_no = 1
comment_all = []
while True:
req_url = news_url.format(page_no)
html = requests.get(req_url, headers = header)
news_text = html.text
news_text = news_text.replace("_callback(","")
comment_text = json.loads(news_text[:-2])
temp_comment_list = [comment_info['contents'] for comment_info in comment_text['result']['commentList']]
comment_all.extend(temp_comment_list)
page_no+=1
if len(comment_all) > 100:
break
5. 마무리하면서
이렇게 뉴스기사 1개에 대한 댓글을 수집하는 코드를 짜봤다. 다음엔 참고 사이트를 참고해서 더 많은 기사에 대한 댓글을 웹스크래핑해보도록 하자.
Related Posts
| 네이버부스트코스 코칭스터디 9기 'AI Basic 2023' 후기 | After Boostcourse 9th Study | |
| Tips | DeepLearning Technique | |
|
Tips | Ensemble Models | sklearn 트리 앙상블 모델 4가지 |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).