Tips | Ensemble Models |
[ ML ] sklearn 트리 앙상블 모델 4가지
앙상블 Ensemble
앙상블이란 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법으로, 해당 포스트는 그 중에서도
1. RandomForest
2. ExtraTree
3. GradientBoosting
4. Histogram-based-Gradient-Boosting
이렇게 총 4가지의 트리 앙상블 모델을 공부하고 정리하였다.
1. 랜덤 포레스트 RandomForest

랜덤 포레스트는 지도 머신러닝 알고리즘으로, Tree가 모여 Forest를 이룬다고 해서 Forest라는 이름이 붙었다. 여기서 Tree는 결정 트리 (Decision Tree)를 말한다. Train data에 overfitting될 수 있는 결정 트리의 단점을 보완하기 위해 여러 개의 결정 트리를 통해 예측하여 overfitting을 줄인다.
# RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
RandomForestClassifier(n_estimators=100, criterion="gini", max_depth=None,
min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.0,
max_featrues = "sqrt", max_leaf_nodes = None, min_impurity_decrease = 0.0,
boostrap = True, oob_score = False, n_jobs = None, random_state = None,
verbose = 0, warm_start = False, class_weight = None, ccp_alpha = 0.0, max_samples = None)
# RandomForestRegressor
from sklearn.ensemble import RandomForestRegressor
RandomForestRegressor(n_estimators = 100, criterion = "squared_error", max_depth = None,
min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.0,
max_featrues = 1.0, max_leaf_nodes = None, min_impurity_decrease = 0.0,
boostrap = True, oob_score = False, n_jobs = None, random_state = None,
verbose = 0, warm_start = False, ccp_alpha = 0.0, max_samples = None)
2. 엑스트라 트리 ExtraTree
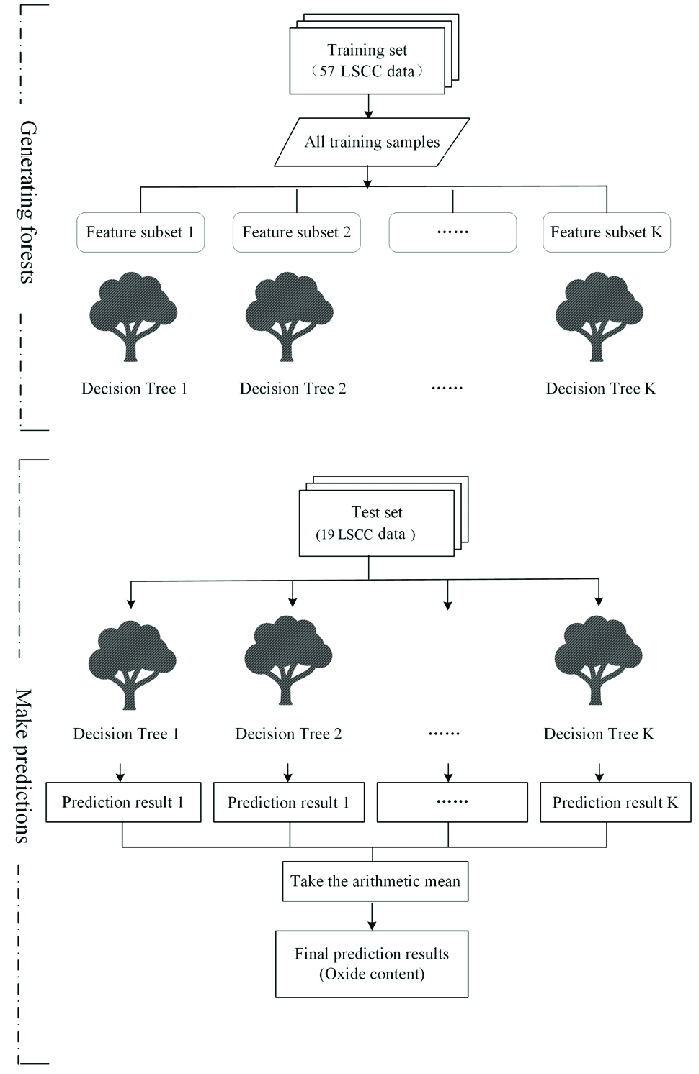
랜덤 포레스트와 전체적인 원리는 비슷하다.
🤔 그렇다면 어떤 점이 다를까?
- Bootstrap 이용 여부
- Random Forest는 bootstrap sampling을 사용하지만
- Extra Tree는 이를 사용하지 않고 전체 train dataset을 사용함
- 트리 분할 시 변수 선택 과정
- Random Forest는 각각의 트리에서, boostrap sampling된 데이터를 바탕으로 랜덤한 features를 사용하여 만들 수 있는 최적의 트리를 생성
- Extra Tree는 각각의 트리에서, original data를 바탕으로 랜덤한 feature 사용하지만, 최적의 트리를 만드는 것이 아니라 각각 split 지점에서 무작위의 feature를 선택하여 그 feature에 대한 최적의 partition을 찾아 split을 진행한다.
✅ Random Forest에 비해 Extra Tree는
- 연산량이 적다.
- 랜덤성이 증가하면서 모델의 bias는 증가
- 그러나 Random Forest보다 랜덤성이 조금 더 크기 때문에 더 많은 결정트리를 학습해야함
➡️ 일반적으로 Random Forest가 더 선호된다.
# ExtraTreesClassifier
from sklearn.ensemble import ExtraTreesClassifier
ExtraTreesClassifier(n_estimators=100, *, criterion='gini', max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0,
bootstrap=False, oob_score=False, n_jobs=None, random_state=None, verbose=0,
warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)
# ExtraTreesRegressor
from sklearn.ensemble import ExtraTreesRegressor
ExtraTreesRegressor(n_estimators=100, *, criterion='squared_error', max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features=1.0, max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=False,
oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False,
ccp_alpha=0.0, max_samples=None)
3. 그래디언트 부스팅 Gradient Boosting
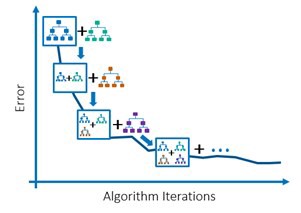
Gradient Boosting의 기본 아이디어는 얕은 트리와 간단한 모델 (약한 학습기)를 많이 연결하는 것이다. Random Forest와 달리 랜덤성이 있는 게 아니라 이전 트리의 오차를 보완하는 방식을 이용해 순차적으로 트리를 만든다. Random Forest보다는 매개변수 설정에 좀 더 민감하지만, 잘 조정하면 더 좋은 성능을 얻을 수 있다.
각 트리의 깊이가 얕아서 overfitting을 피하기에 아주 좋다.
# GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingClassifier
GradientBoostingClassifier(*, loss='log_loss', learning_rate=0.1, n_estimators=100,
subsample=1.0, criterion='friedman_mse', min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
min_impurity_decrease=0.0, init=None, random_state=None, max_features=None,
verbose=0, max_leaf_nodes=None, warm_start=False, validation_fraction=0.1,
n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
# GradientBoostingRegressor
from sklearn.ensemble import GradientBoostingRegressor
GradientBoostingRegressor(*, loss='squared_error', learning_rate=0.1, n_estimators=100,
subsample=1.0, criterion='friedman_mse', min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
min_impurity_decrease=0.0, init=None, random_state=None, max_features=None,
alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False,
validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
4. 히스토그램 기반 그래디언트 부스팅 Histogram-based-Gradient-Boosting
sklearn의 히스토그램 기반 그래디언트 부스팅은 마이크로소프트의 LightGBM에 영향을 받았고, 이 알고리즘을 구현한 라이브러리는 sklearn 이외에도 여러 개가 있다.
입력 특성을 256개의 정수 구간으로 나누며, 그 중 하나는 누락된 값을 위해 사용한다.
입력에 누락된 특성이 있더라도 전처리를 하지 않아도 되며, 일반적으로 다른 부스팅 모델에 비해 기본 매개변수에서 안정적인 성능을 얻을 수 있다. 또한, 대용량의 데이터를 다룰 때 Gradient Boosting보다 빠르게 작동한다. overfitting을 잘 억제하면서 Gradient Boosting보다는 좀 더 높은 성능을 제공한다고 한다.
# HistGradientBoostingClassifier
from sklearn.ensemble import HistGradientBoostingClassifier
HistGradientBoostingClassifier(loss='log_loss', *, learning_rate=0.1,
max_iter=100, max_leaf_nodes=31,
max_depth=None, min_samples_leaf=20,
l2_regularization=0.0, max_bins=255,
categorical_features=None, monotonic_cst=None,
warm_start=False, early_stopping='auto',
scoring='loss', validation_fraction=0.1,
n_iter_no_change=10, tol=1e-07,
verbose=0, random_state=None)
Feature Importance를 구하는 함수가 따로 없기 때문에 다음 코드를 이용하면 된다.
from sklearn.inspection import permutation_importance
sklearn.inspection.permutation_importance(estimator, X, y, *,
scoring=None, n_repeats=5,
n_jobs=None,
random_state=None,
sample_weight=None,
max_samples=1.0)
참고
Related Posts
| 네이버부스트코스 코칭스터디 9기 'AI Basic 2023' 후기 | After Boostcourse 9th Study | |
| Tips | DeepLearning Technique | |
|
Tips | Cloud & ML Platform | 클라우드 머신러닝 플랫폼 선택 기준 12가지 |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).