Table of Contents
참고
- 간단한 딥러닝 모델 성능 향상 테크닉 2가지 - Input Mixup & Label Smoothing
- 2. Label Smoothing
- 💻 코드 실습 - Input Mixup & Label Smoothing
간단한 딥러닝 모델 성능 향상 테크닉 2가지 - Input Mixup & Label Smoothing
본 포스트에서는 최근 딥러닝 모델 학습에서 많이 사용되며, 모델의 구조를 바꾸지 않고 간단하게 딥러닝 모델 성능을 향상시킬 수 있는 2가지 방법에 대해 공부하고 정리하였다.
1. Mixup Training
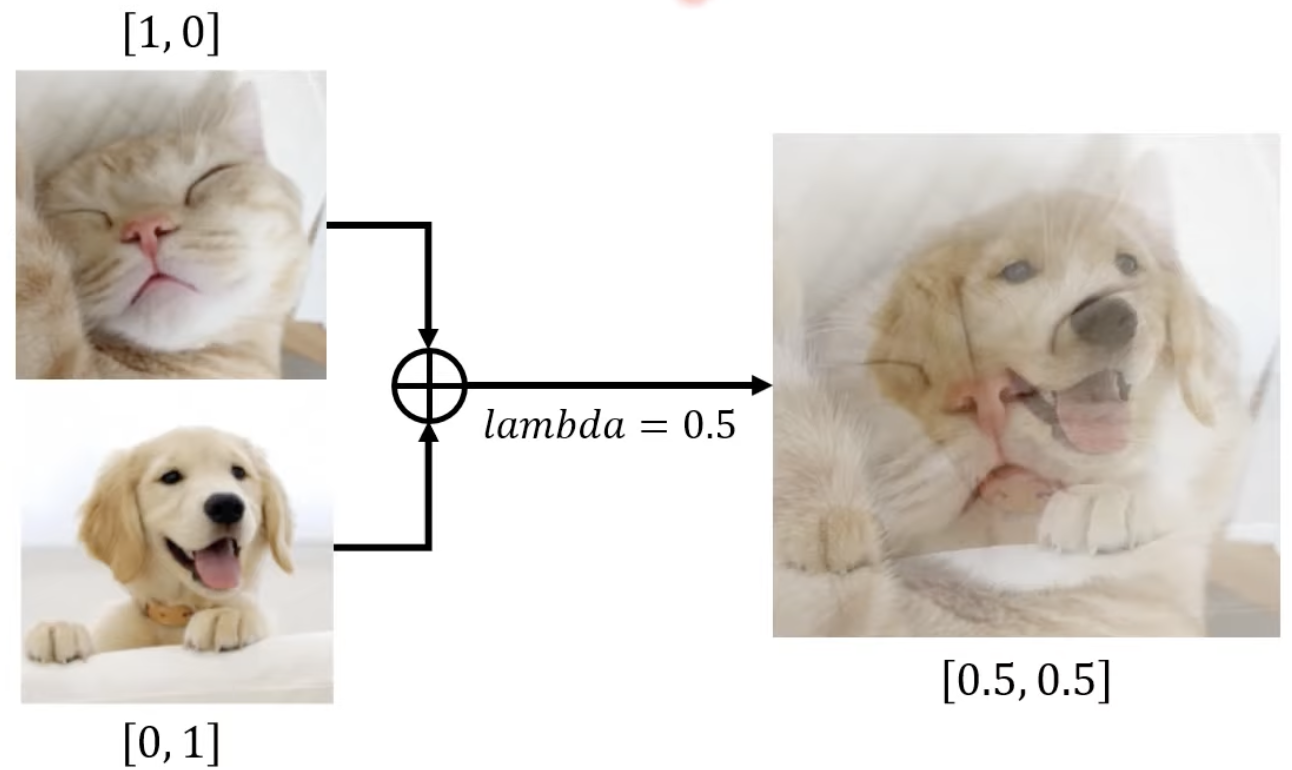
학습을 진행할 때 랜덤하게 두 개의 샘플을 뽑아서 MIXUP 한 뒤에 학습에 사용한다. 위 그림에서는 lambda가 0.5로 설정되었지만, 보통은 특정 이미지에 더 높은 값이 부여된다.
🤔 Mixup을 사용하면 왜 성능이 더 좋아질까?
1️⃣ Data Augmentation
랜덤성을 띠는 형태로 데이터 증진을 수행하면 실제 모델은 더욱 더 많은 데이터로 학습을 한 것과 같은 효과
2️⃣ Over-Fitting 방지
어느 정도 Regularization을 수행하는 효과
2. Label Smoothing
Label Smoothing은 일반화 Generalization 성능을 높이기 위해 label을 smoothing하는 방법이다. Mixup Training과 유사한 부분이 있지만 가장 큰 차이점은 이미지는 건드리지 않고 label만 바꿔준다는 것이다.
➡️ 정답 레이블에 대해서만 100% 확률을 부여하지 않는다.
Hard Label 방식 정답 레이블에 대해서만 1, 나머지 레이블은 0으로 부여하는 것이 아니라
Soft Label 방식Smoothing 작업을 통해 정답 레이블은 1과 가까운 값으로, 나머지 레이블에 0보다 조금 큰 값을 넣어주는 작업이다.
사람의 실수에 의해서 잘못 labeling 된 값이 존재할 수 있기 때문에 하나의 레이블에 대해서 높은 Confidence 를 갖게 하는 것은 다양한 문제를 야기할 수 있다.
💻 코드 실습 - Input Mixup & Label Smoothing
필요한 라이브러리 구현
import numpy as np
mixup_alpha = 1.0
def mixup_data(x, y):
lam = np.random.beta(mixup_alpha, mixup_alpha)
batch_size = x.size()[0]
index = torch.randperm(batch_size).cuda()
mixed_x = lam * x + (1 - lam) * x[index]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
class LabelSmoothingCrossEntropy(nn.Module):
def __init__(self):
super(LabelSmoothingCrossEntropy, self).__init__()
def forward(self, y, targets, smoothing=0.1):
confidence = 1. - smoothing
log_probs = F.log_softmax(y, dim=-1) # 예측 확률 계산
true_probs = torch.zeros_like(log_probs)
true_probs.fill_(smoothing / (y.shape[1] - 1))
true_probs.scatter_(1, targets.data.unsqueeze(1), confidence) # 정답 인덱스의 정답 확률을 confidence로 변경
return torch.mean(torch.sum(true_probs * -log_probs, dim=-1)) # negative log likelihood
환경 설저 및 학습 (Training) 함수 정의
device = 'cuda'
net = ResNet18()
net = net.to(device)
learning_rate = 0.1
file_name = 'resnet18_cifar10.pth'
criterion = LabelSmoothingCrossEntropy()
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=0.9, weight_decay=0.0002)
def train(epoch):
print('\n[ Train epoch: %d ]' % epoch)
net.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
inputs, targets_a, targets_b, lam = mixup_data(inputs, targets)
optimizer.zero_grad()
outputs = net(inputs)
loss = mixup_criterion(criterion, outputs, targets_a, targets_b, lam)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
current_correct = (lam * predicted.eq(targets_a).sum().item() + (1 - lam) * predicted.eq(targets_b).sum().item())
correct += current_correct
if batch_idx % 100 == 0:
print('\nCurrent batch:', str(batch_idx))
print('Current batch average train accuracy:', current_correct / targets.size(0))
print('Current batch average train loss:', loss.item() / targets.size(0))
print('\nTotal average train accuarcy:', correct / total)
print('Total average train loss:', train_loss / total)
def test(epoch):
print('\n[ Test epoch: %d ]' % epoch)
net.eval()
loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(test_loader):
inputs, targets = inputs.to(device), targets.to(device)
total += targets.size(0)
outputs = net(inputs)
loss += criterion(outputs, targets).item()
_, predicted = outputs.max(1)
correct += predicted.eq(targets).sum().item()
print('\nTotal average test accuarcy:', correct / total)
print('Total average test loss:', loss / total)
state = {
'net': net.state_dict()
}
if not os.path.isdir('checkpoint'):
os.mkdir('checkpoint')
torch.save(state, './checkpoint/' + file_name)
print('Model Saved!')
학습 진행
import time
def adjust_learning_rate(optimizer, epoch):
lr = learning_rate
if epoch >= 50:
lr /= 10
if epoch >= 100:
lr /= 10
for param_group in optimizer.param_groups:
param_group['lr'] = lr
start_time = time.time()
for epoch in range(0, 150):
adjust_learning_rate(optimizer, epoch)
train(epoch)
test(epoch)
if epoch % 10 == 0 :
print('\nTime elapsed:', time.time() - start_time)
참고
[YouTube] 간단한 딥러닝 모델 성능 향상 테크닉 2가지 소개 (코드 실습 포함) - Input Mixup과 Label Smoothing
Related Posts
| 네이버부스트코스 코칭스터디 9기 'AI Basic 2023' 후기 | After Boostcourse 9th Study | |
|
Tips | Ensemble Models | sklearn 트리 앙상블 모델 4가지 |
|
|
Tips | Cloud & ML Platform | 클라우드 머신러닝 플랫폼 선택 기준 12가지 |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).