Tips | Cloud & ML Platform |
Table of Contents
3. 모델 구축을 위한 온라인 환경 지원 4. 수직 및 수평 확장 학습 지원 5. AutoML 및 자동 특성 엔지니어링 지원 6. 우수한 머신러닝과 딥 러닝 프레임워크 지원 7. 사전 학습 모델을 제공하고 전이 학습을 지원하는지 8. 튜닝된 AI 서비스 제공 9. 실험 관리 10. 예측을 위한 모델 배포 지원 11. 예측 성능 모니터링 12. 비용 통제 마무리하면서 참고
클라우드 머신러닝 플랫폼 선택 기준 12가지
원문 : 클라우드 머신러닝 플랫폼 선택 기준 12가지 내용을 내 눈에 들어오도록 정리해놓았다. 자세한 내용은 원문에 들어가서 확인하면 좋을 것 같다.
1. 데이터와 가까울 것
모델을 구축하는 데 필요한 많은 양의 데이터가 있다고 해도 데이터를 가져오는 시간이 길어진다면 효용이 떨어진다. 무한한 대역폭을 가진 완벽한 네트워크라고 해도 빛의 속도는 넘을 수 없으며, 멀리 떨어져 있다면 시간 지연의 문제를 불러올 수 있다.
🥇 데이터 집합이 매우 크다면
가장 이상적인 상황은 데이터가 있는 위치에 모델을 구축해서 대량 데이터를 전송할 필요가 없도록 하는 것! 제한된 범위에서 이런 서비스를 제공하는 데이터베이스는 몇 가지가 있다고 한다.
🥈 차선책
데이터가 모델 구축 SW와 동일한 고속 네트워크에 위치하는 형태!
일반적으로 같은 데이터 센터 내에 위치하는 경우를 말한다.
데이터의 용량이 TB 이상인 경우 한 클라우드 가용성 영역 내에서 이루어지는 데이터센터 간의 데이터 전송에도 큰 지연이 발생할 수 있다.
💩 최악의 경우
1. 대역폭이 제한되어 있고,
2. 지연이 높은 경로를 통해
3. 장거리로
4. 대량의 데이터를 전송하는 경우
실제로 오스트레일리아로 가는 환태평양 케이블에서 이 문제가 두드러진다고 한다.
2. ETL 또는 ELT 파이프라인 지원
ETL 및 ELT는 DB에서 보편적으로 사용되는 2가지 데이터 파이프라인 구성이다. ML과 DL로 인해 두 파이프라인의 필요성이 커졌다. 일반적으로 빅데이터에서 가장 많은 시간이 소비되는 단계는 Load 단계이므로 ELT가 더 높은 유연성을 제공한다.
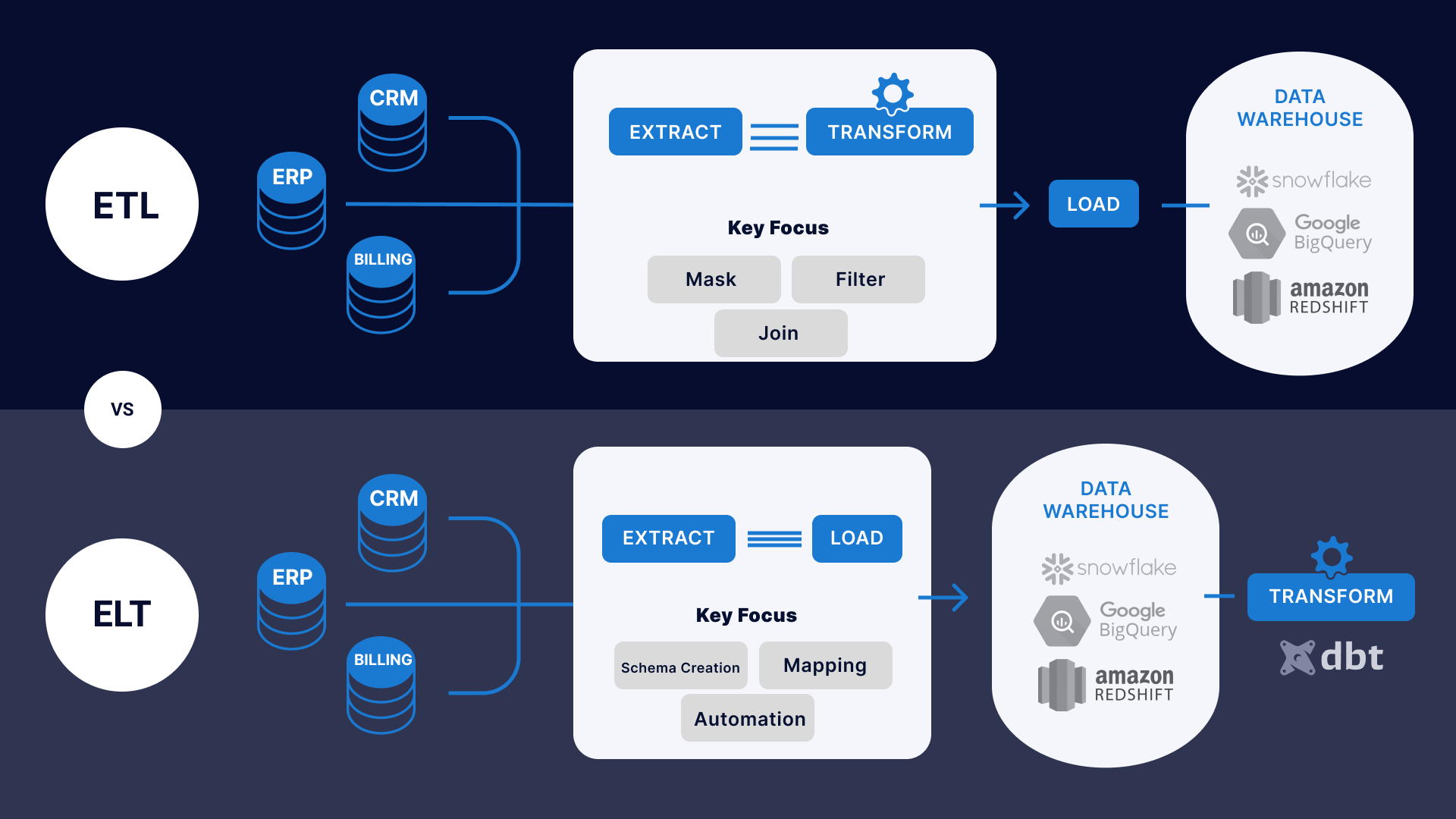
ETL Extract, Transform, Load
데이터소스에서 가져온 rawdata로 데이터 웨어하우스에 바로 저장할 수 없기 때문에 ETL 과정이 필요하다.
핵심은 Transform하는 단계
비즈니스 또는 분석 용도에 맞춰 데이터를 잘 정제하는 게 중요하다. 데이터 크기가 크면 클수록, Transform하는 시간도 오래 걸린다.
ETL 파이프라인이 설계된 후에는 1일 1회 등의 방식으로 업데이트된 내용을 다시 가져와서 새로운 내용을 저장한다.
ELT Extract, Load, Transform
요즘은 ETL보다 ELT를 선호한다. 데이터가 점점 많아지면서 Transform하는데 시간이 오래 걸리면서 ETL보다는 먼저 적재를 해놓고 어떻게 변형할지 고민하는 ELT 과정이 더 자주 쓰이고 있다. 또한, cpu, 메모리, ssd, hdd 등 리소스 가격의 인하와 글라우드 사용료 인하로 인해 전부 다 저장해버리는 게 낫겠다는 컨셉에서 데이터를 먼저 저장하게 되었다고도 한다.
모든 데이터 소스를 하나의 공간 DataLake로 적재한 뒤, 그 용도에 따라서 필요한 경우 툴이나 시스템이 직접 변형하게 하는 과정이다.
🤔 Data Lake vs Data Warehouse
Data Warehouse
- 어느 정도 가치가 있고 구조화된 데이터들이 모여있는 곳
- 공간에 제약이 있음 -> 필요한 모든 데이터를 저장하지 않고 최근 데이터만 저장
- BI툴과 연결해서 시각화 -> 지표계산 하는 것이 일반적
Data Lake
- Data Warehouse 기반 파이프라인보다 훨씬 더 큰 개념
- 구조화된 데이터도 있지만 비구조화된 데이터 존재
- DW보다 용량 크고, 비용 저렴 -> 모든 데이터 저장
3. 모델 구축을 위한 온라인 환경 지원
☎️ PAST
모델 구축을 위해서 데이터를 데스크탑으로 가져와야 했다.
📱 NOW
ML과 DL 모델을 구축하는 데 필요한 대용량의 데이터를 얻는 게 가능해지면서 이 데이터를 데스크탑에 전부 저장하기 어려워졌다. 데스크탑으로 데이터를 샘플링해서 다운로드 받아 분석 및 모델 구축을 할 수 있지만, 실제로 배포할 모델을 위해서는 전체 데이터에 접근할 수 있어야 한다.
주피터 노트북(Jupyter Notebook), 주피터랩(JupyterLab), 아파치 제플린(Zeppelin)과 같은 웹 기반 개발 환경은 모델 구축에 적합하다. 데이터가 노트북 환경과 같은 클라우드에 있다면 데이터 이동에 따른 시간 낭비를 최소화하면서 데이터를 분석할 수 있다.
4. 수직 및 수평 확장 학습 지원
노트북이 여러 개의 큰 가상 머신이나 컨테이너에서 실행되는 학습 작업을 생성할 수 있다면 많은 도움이 된다.
또, 학습에서 GPU, TPU, FPGA와 같은 가속기에 액세스할 수 있는 경우 역시 도움이 된다.
5. AutoML 및 자동 특성 엔지니어링 지원
AutoML 시스템은 다수의 모델을 시도해서 최적의 목적 함수 값을 산출하는 모델을 찾아준다. 또한 우수한 AutoML 시스템은 특성 엔지니어링을 수행하고 리소스를 효과적으로 사용해서 가능한 최선의 특성 집합을 가진 최선의 모델을 찾을 수 있다.
6. 우수한 머신러닝과 딥 러닝 프레임워크 지원
대부분의 데이터 과학자는 각자 머신러닝과 딥 러닝에 선호하는 프레임워크와 프로그래밍 언어가 있다. 주로 이용하는 프레임워크와 프로그래밍 언어는 다음과 같다.
- Python
- ML : Scikit Learn
- DL : Tensorflow, Pytorch, Keras, MXNet
- Scalar
- ML : 스파크 MLlib
- 이외에
- R은 많은 네이티브 머신러닝 패키지를 가지고 있고, 좋은 파이썬 인터페이스도 있다.
- 자바에서는 H2O.ai와 자바-ML, 딥 자바 라이브러리가 높게 평가된다.
클라우드 머신러닝과 딥 러닝 플랫폼에는 대체로 자체 알고리즘 모음이 있으며, 많은 경우 적어도 하나의 언어로, 또는 특정 진입점이 있는 컨테이너 형태로 외부 프레임워크를 지원한다. 경우에 따라 자체 알고리즘과 통계 방법을 플랫폼의 AutoML 기능에 통합해서 편리하게 사용할 수도 있다.
일부 클라우드 플랫폼은 주요 딥 러닝 프레임워크를 튜닝한 자체 버전을 제공한다. 예를 들어 AWS는 최적화된 텐서플로우 버전을 제공하면서 심층 신경망 학습에서 거의 선형적인 확장성을 달성할 수 있다고 주장한다.
7. 사전 학습 모델을 제공하고 전이 학습을 지원하는지
사전 학습된 모델이 제공된다면, 많은 시간과 컴퓨팅 리소스를 소비해 자체 모델을 학습시키지 않아도 된다.
예를 들어, 방대한 ImageNet DB를 대상으로 한 첨단 심층 신경망 학습에는 몇 주 정도의 긴 시간이 소요될 수 있으므로 사전 학습된 모델을 사용하는 편이 합리적이다!
반면, 사전 학습된 모델로 자신이 원하는 객체를 식별하지 못할 수도 있다. 전이 학습은 전체 신경망 학습을 위한 시간 및 비용 소비 없이 자신의 특정 데이터 집합에 맞게 신경망의 마지막 몇 개 계층을 맞춤 설정하는 데 도움이 된다.
8. 튜닝된 AI 서비스 제공
주요 클라우드 플랫폼은 이미지 식별뿐만 아니라 많은 응용 분야를 위한 강력하고 튜닝된 AI 서비스를 제공한다.
| 언어 번역, 음성-텍스트 변환, 텍스트-음성 변환, 예측, 추천 등
이러한 서비스는 기업에서 일반적으로 사용할 수 있는 것보다 더 많은 데이터를 사용해서 이미 학습 및 테스트를 거쳤다. 또한 전세계에서 이용해도 우수한 응답 시간을 보장하기 위해 가속기를 포함한 충분한 계산 리소스를 갖춘 서비스 엔드포인트에 이미 구축됐다.
9. 실험 관리
데이터셋에 맞는 최적의 모델을 찾으려면 일일이 찾거나 AutoML을 사용하는 방법이다.
우수한 클라우드 머신러닝 플랫폼은 train data와 test data 모두에 대해 각 실험의 목적 함수 값과 모델의 크기 및 혼동 행렬을 보고 비교할 수 있는 방법을 제공한다. 이러한 모든 요소를 그래프화할 수 있는 기능은 확실히 도움이 된다.
10. 예측을 위한 모델 배포 지원
최적의 모델을 찾았다면 모델을 쉽게 배포할 수 있는 방법도 찾아야 한다. 동일 목적으로 여러 모델을 배포하는 경우 A/B 테스트를 위해 모델 간에 트래픽을 분할할 방법도 필요하다.

| A/B 테스트
- 분할 테스트 / 버킷 테스트 라고도 함
- 두 가지 콘텐츠를 비교하여 방문자 / 뷰어가 더 높은 관심을 보이는 버전을 확인한다.
- 주요 측정 지표를 기반으로 가장 성공적인 버전을 측정하기 위해
- 변형(B) 버전과 비교하여 컨트롤(A) 버전을 검증한다.
11. 예측 성능 모니터링
세상은 변하고 데이터 또한 세상과 함께 변한다. 즉, 모델 배포가 끝이 아니라 예측을 위해 제출되는 데이터를 계속해서 모니터링해야 한다.
데이터가 원래 학습 데이터셋 기준에서 큰 폭으로 바뀌기 시작하면 모델 재학습이 필요하다.
12. 비용 통제
모델에 의해 발생하는 비용을 통제할 방법이 필요하다. 프로덕션 추론을 위한 모델 배포 비용은 딥 러닝 비용의 90%까지 차지하기도 하며, 이렇게 되면 학습에 소요되는 비용은 10%에 불과하다.
THEN HOW?
예측 비용을 통제하는 최선의 방법은 모델의 부하와 복잡성에 따라 다르다. 부하가 높다면 가속기를 사용하여 가상 머신 인스턴스 추가를 피할 수 있다. 부하가 변동되는 경우엔, 부하의 상승 / 하락에 맞춰 인스턴스나 컨테이너의 크기 또는 수를 동적으로 바꿀 수 있다. 부하가 낮거나 간헐적인 경우에는 아주 작은 인스턴스를 부분 가속기와 함께 사용해서 예측을 처리하는 방법이 있다.
마무리하면서
머신러닝 공부하면서 모델의 배포까지는 생각해보지 못했는데 해당 글을 읽고 서비스를 배포할 때는 생각보다 많은 것을 고려해야된다는 것을 알았다. 앞으로 더 넓게, 멀리 생각해보는 연습을 해야겠다.
참고
Related Posts
| 네이버부스트코스 코칭스터디 9기 'AI Basic 2023' 후기 | After Boostcourse 9th Study | |
| Tips | DeepLearning Technique | |
|
Tips | Ensemble Models | sklearn 트리 앙상블 모델 4가지 |
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).