[ NLP ] GAN : Generative Adversarial Nets
본 포스트에서는 문장 생성 모델에 관한 프로젝트를 진행하기 위해 공부한 내용을 정리하였다. GAN에 대해 알아보자.
Generative Model 의 목표
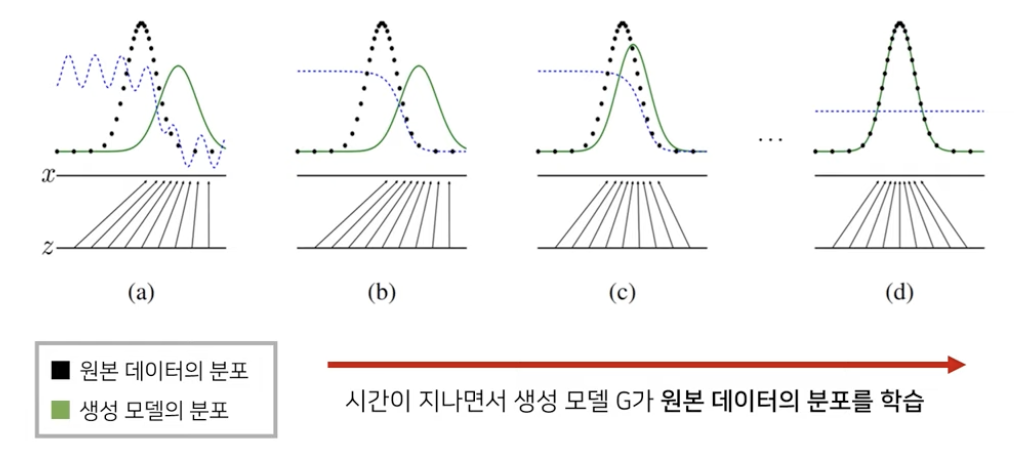
시간이 지나면서 생성 모델이 원본 데이터의 분포를 학습한다.
학습이 잘 되었다면 통계적으로 평균적인 특징을 가지는 데이터를 쉽게 생성할 수 있다. 이때 판별 모델은 더 이상 진짜 이미지와 가짜 이미지를 구분할 수 없기 때문에 분포가 1/2 로 수렴한다.
GAN이란
Generative Adversarial Networks의 약자로, 실제로 존재하지 않지만 있을법한 이미지나 텍스트 등 여러 데이터를 생성해 내는 모델이다.
이름에서 알 수 있듯이 GAN은 서로 다른 두 개의 네트워크를 적대적으로(adversarial) 학습시키며 실제 데이터와 비슷한 데이터를 생성(generative)해내는 모델이며 이렇게 생성된 데이터에 정해진 label값이 없기 때문에 비지도 학습 기반 생성모델로 분류된다.
이때 두 개의 네트워크는 생성자 generator 와 판별자 discriminator 를 말한다. 학습이 다 된 이후에, 모델은 생성자라고 할 수 있으며 판별자는 이 생성자가 잘 학습할 수 있도록 도와주기 위한 목적으로 많이 사용한다. 이 두 개의 네트워크를 함께 학습시키면서 결과적으로 생성 모델을 학습할 수 있게 된다 !
[ 목적 함수 ]
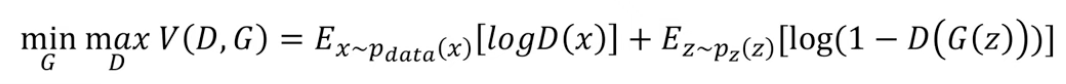
생성자 G 는 함수 V 의 값을 낮추고자 노력하고 판별자 D 는 높이려고 노력한다. 이 함수를 통해 생성자는 이미지 분포를 학습할 수 있다.
1️⃣ 이미지
데이터에서 여러 개의 데이터 (이미지) 를 뽑아와서 log 변환해준 후의 기댓값, 즉 평균값
2️⃣ 노이즈
노이즈를 샘플링해와서 생성자 G에 넣어서 가짜 이미지를 만든 후 판별자 D에 넣은 값을 1에서 빼서 Log를 취한 값의 평균값
생성자에 대한 개념이 포함. 기본적으로 생성자는 노이즈 벡터로부터 이미지를 받아와서 새로운 이미지를 만들 수 있다. 진짜 이미지는 1, 가짜 이미지는 0.
모델 학습

매 epoch당 Descriminator를 먼저 학습하고, Generator의 학습이 이루어진다.
Descriminator는 기울기 (Stochastic gradient) 가 증가하는 방향으로 학습되고, generator는 기울기가 감소하는 방향으로 학습된다.
GAN 특징
- Not cherry-picked
- 이미지를 선별해서 넣은 게 아니라 랜덤하게 넣어줌
- Not memorized the training set
- 학습 데이터를 단순히 암기한 것이 아님
- Competitive with the better generative models
- 이전의 다른 생성 모델과 비교했을 때 충분히 좋은 성능이 나옴
- Images represent sharp
- Blurry하게 이미지를 생성하지 않고 꽤 선명하게 생성
- 문장이 길어질수록 생성된 문장의 품질이 안 좋아짐
💻 코드 실습 - GAN
해당 코드는 MNIST 데이터셋을 가지고 가장 기본적인 GAN 모델을 학습한 코드이다.
생성자 Generator 및 판별자 Discriminator 모델 정의
latent_dim = 100
# 생성자(Generator) 클래스 정의
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 하나의 블록(block) 정의
def block(input_dim, output_dim, normalize=True):
layers = [nn.Linear(input_dim, output_dim)]
if normalize:
# 배치 정규화(batch normalization) 수행(차원 동일)
layers.append(nn.BatchNorm1d(output_dim, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
# 생성자 모델은 연속적인 여러 개의 블록을 가짐
self.model = nn.Sequential(
*block(latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, 1 * 28 * 28),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), 1, 28, 28)
return img
# 판별자(Discriminator) 클래스 정의
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(1 * 28 * 28, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
# 이미지에 대한 판별 결과를 반환
def forward(self, img):
flattened = img.view(img.size(0), -1)
output = self.model(flattened)
return output
학습 데이터셋 불러오기
transforms_train = transforms.Compose([
transforms.Resize(28),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
train_dataset = datasets.MNIST(root="./dataset", train=True, download=True, transform=transforms_train)
dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=4)
모델 학습 및 샘플링
# 생성자(generator)와 판별자(discriminator) 초기화
generator = Generator()
discriminator = Discriminator()
generator.cuda()
discriminator.cuda()
# 손실 함수(loss function)
adversarial_loss = nn.BCELoss()
adversarial_loss.cuda()
# 학습률(learning rate) 설정
lr = 0.0002
# 생성자와 판별자를 위한 최적화 함수
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
import time
n_epochs = 200 # 학습의 횟수(epoch) 설정
sample_interval = 2000 # 몇 번의 배치(batch)마다 결과를 출력할 것인지 설정
start_time = time.time()
for epoch in range(n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# 진짜(real) 이미지와 가짜(fake) 이미지에 대한 정답 레이블 생성
real = torch.cuda.FloatTensor(imgs.size(0), 1).fill_(1.0) # 진짜(real): 1
fake = torch.cuda.FloatTensor(imgs.size(0), 1).fill_(0.0) # 가짜(fake): 0
real_imgs = imgs.cuda()
""" 생성자(generator)를 학습합니다. """
optimizer_G.zero_grad()
# 랜덤 노이즈(noise) 샘플링
z = torch.normal(mean=0, std=1, size=(imgs.shape[0], latent_dim)).cuda()
# 이미지 생성
generated_imgs = generator(z)
# 생성자(generator)의 손실(loss) 값 계산
g_loss = adversarial_loss(discriminator(generated_imgs), real)
# 생성자(generator) 업데이트
g_loss.backward()
optimizer_G.step()
""" 판별자(discriminator)를 학습합니다. """
optimizer_D.zero_grad()
# 판별자(discriminator)의 손실(loss) 값 계산
real_loss = adversarial_loss(discriminator(real_imgs), real)
fake_loss = adversarial_loss(discriminator(generated_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
# 판별자(discriminator) 업데이트
d_loss.backward()
optimizer_D.step()
done = epoch * len(dataloader) + i
if done % sample_interval == 0:
# 생성된 이미지 중에서 25개만 선택하여 5 X 5 격자 이미지에 출력
save_image(generated_imgs.data[:25], f"{done}.png", nrow=5, normalize=True)
# epoch 10마다 로그(log) 출력
if epoch % 10 == 0:
print(f"[Epoch {epoch}/{n_epochs}] [D loss: {d_loss.item():.6f}] [G loss: {g_loss.item():.6f}] [Elapsed time: {time.time() - start_time:.2f}s]")
생성된 이미지 출력
from IPython.display import Image
Image('92000.png')
참고
[YouTube] GAN:Generative Adversarial Networks
Make GANs Training Easier for Everyone : Generate Images Following a Sketch
논문 Generative Adversarial Networks (NIPS 2014)
💙 You need to log in to GitHub to write comments. 💙
If you can't see comments, please refresh page(F5).